
현대 웹 개발에서 네이버 검색 API 활용은 필수적인 기술로 자리잡았습니다.
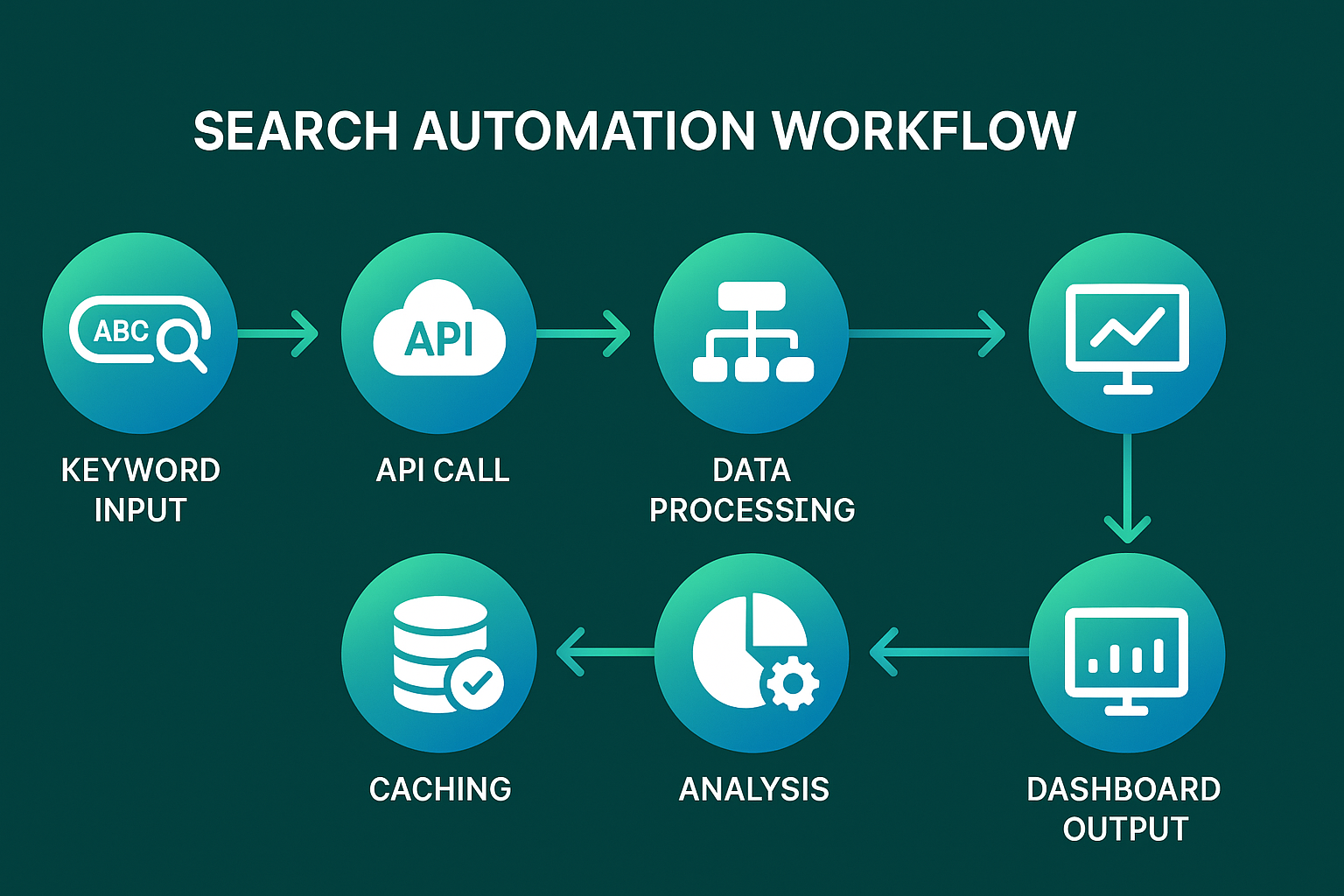
수동으로 데이터를 수집하던 시대는 지났고, 이제는 검색 자동화를 통해 효율적으로 대량의 정보를 처리할 수 있습니다.
이 글에서는 네이버 검색 API의 핵심 활용법부터 고급 최적화 기법까지 실무에 바로 적용할 수 있는 노하우를 전수합니다.
네이버 검색 API란? 핵심 개념 이해하기
API(Application Programming Interface)는 두 소프트웨어가 서로 통신할 수 있게 해주는 인터페이스입니다.
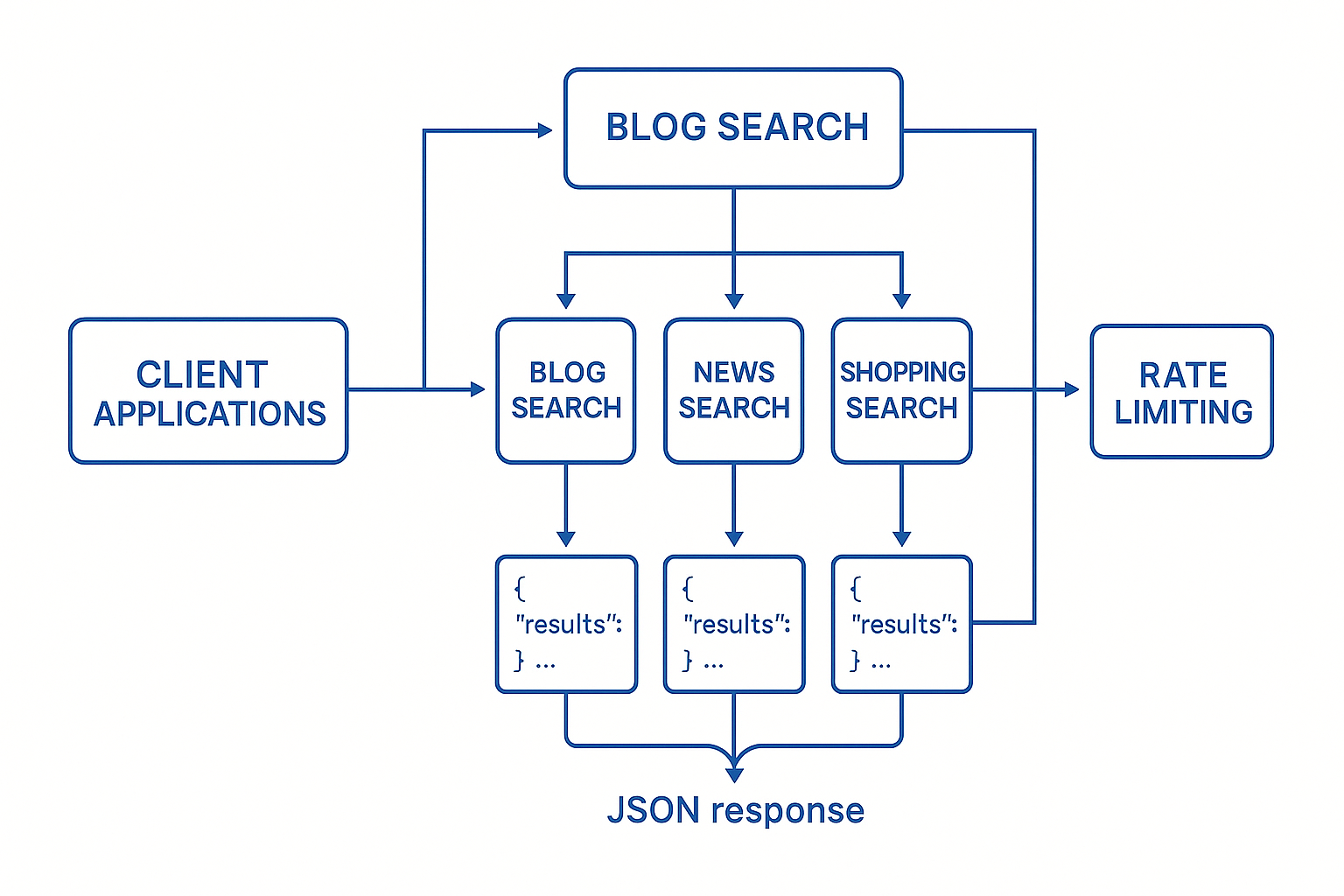
네이버 검색 API는 네이버 검색 결과를 뉴스, 백과사전, 블로그, 쇼핑, 웹 문서, 전문정보, 지식iN, 책, 카페글 등
분야별로 볼 수 있는 API입니다.
특히 크롤러 개발자들에게는 안정적이고 구조화된 데이터 수집 방법을 제공합니다.
주요 특징과 장점
- 일일 25,000회 무료 호출 제한으로 충분한 테스트 가능
- JSON/XML 형식으로 구조화된 데이터 제공
- RESTful API 구조로 간편한 연동
- 다양한 검색 분야 지원 (블로그, 뉴스, 쇼핑 등)
- 비로그인 방식으로 빠른 개발 가능
네이버 검색 API 시작하기: 단계별 설정 가이드
1. 개발자 센터 등록
먼저 네이버 개발자 센터에 접속하여 계정을 생성합니다.
로그인 후 애플리케이션 등록 메뉴에서 새 프로젝트를 생성하세요.
2. 검색 API 신청
애플리케이션 등록 시 사용 API에서 '검색'을 반드시 선택해야 합니다.
비로그인 오픈 API 환경에서 서비스할 환경(WEB/모바일)을 설정합니다.
3. Client ID와 Secret 발급
클라이언트 아이디와 클라이언트 시크릿은 인증된 사용자인지를 확인하는 수단이며, 애플리케이션이 등록되면 발급됩니다.
이 키값들은 모든 API 호출에 필수적으로 포함되어야 합니다.
4. 기본 설정 코드 예시
import requests
import json
# 네이버 검색 API 기본 설정
CLIENT_ID = "YOUR_CLIENT_ID"
CLIENT_SECRET = "YOUR_CLIENT_SECRET"
BASE_URL = "https://openapi.naver.com/v1/search"
headers = {
'X-Naver-Client-Id': CLIENT_ID,
'X-Naver-Client-Secret': CLIENT_SECRET
}검색 자동화 핵심 기법: 실무 활용 예제
블로그 검색 자동화
블로그 콘텐츠 크롤러 개발에 가장 많이 활용되는 방식입니다.
특정 키워드의 블로그 포스팅을 자동으로 수집하여 트렌드 분석이나 경쟁사 모니터링에 활용할 수 있습니다.
def search_blog_automation(keyword, display=10):
"""블로그 검색 자동화 함수"""
url = f"{BASE_URL}/blog.json"
params = {
'query': keyword,
'display': display,
'start': 1,
'sort': 'sim' # sim(정확도순), date(날짜순)
}
response = requests.get(url, headers=headers, params=params)
if response.status_code == 200:
data = response.json()
return data['items']
else:
print(f"Error: {response.status_code}")
return None뉴스 검색 최적화
실시간 뉴스 모니터링을 위한 검색 자동화 시스템 구축 방법입니다.
특정 이슈나 브랜드 관련 뉴스를 자동으로 수집하여 위기관리나 PR 전략 수립에 활용합니다.
def news_monitoring_system(keywords_list, interval_minutes=30):
"""뉴스 모니터링 자동화 시스템"""
import schedule
import time
def collect_news():
for keyword in keywords_list:
url = f"{BASE_URL}/news.json"
params = {
'query': keyword,
'display': 20,
'start': 1,
'sort': 'date'
}
response = requests.get(url, headers=headers, params=params)
if response.status_code == 200:
news_data = response.json()
# 데이터 저장 로직 구현
save_to_database(keyword, news_data['items'])
schedule.every(interval_minutes).minutes.do(collect_news)
while True:
schedule.run_pending()
time.sleep(1)
고급 최적화 전략: 성능과 효율성 극대화
Rate Limiting 대응 전략
검색 API의 하루 호출 한도는 25,000회입니다.
대규모 크롤러 운영 시 이 제한을 효율적으로 관리하는 것이 핵심입니다.
import time
from functools import wraps
def rate_limiter(calls_per_second=1):
"""API 호출 속도 제한 데코레이터"""
min_interval = 1.0 / calls_per_second
last_called = [0.0]
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
elapsed = time.time() - last_called[0]
left_to_wait = min_interval - elapsed
if left_to_wait > 0:
time.sleep(left_to_wait)
ret = func(*args, **kwargs)
last_called[0] = time.time()
return ret
return wrapper
return decorator
@rate_limiter(calls_per_second=0.5) # 2초에 1번 호출
def optimized_search_call(keyword):
# API 호출 로직
pass캐싱 시스템 구축
동일한 검색어에 대한 반복 호출을 줄이기 위한 캐싱 전략입니다.
Redis나 메모리 캐시를 활용하여 API 호출 비용을 대폭 절감할 수 있습니다.
import redis
import pickle
from datetime import datetime, timedelta
class SearchAPICache:
def __init__(self, redis_host='localhost', redis_port=6379):
self.redis_client = redis.Redis(host=redis_host, port=redis_port)
self.cache_expiry = 3600 # 1시간 캐시
def get_cached_result(self, search_type, keyword):
"""캐시된 검색 결과 조회"""
cache_key = f"search:{search_type}:{keyword}"
cached_data = self.redis_client.get(cache_key)
if cached_data:
return pickle.loads(cached_data)
return None
def cache_result(self, search_type, keyword, data):
"""검색 결과 캐싱"""
cache_key = f"search:{search_type}:{keyword}"
self.redis_client.setex(
cache_key,
self.cache_expiry,
pickle.dumps(data)
)병렬 처리를 통한 성능 향상
다중 키워드 검색 자동화 시 병렬 처리로 처리 속도를 대폭 향상시킬 수 있습니다.
import concurrent.futures
import threading
class ParallelSearchProcessor:
def __init__(self, max_workers=5):
self.max_workers = max_workers
self.thread_local = threading.local()
def get_session(self):
"""스레드별 세션 관리"""
if not hasattr(self.thread_local, 'session'):
self.thread_local.session = requests.Session()
self.thread_local.session.headers.update(headers)
return self.thread_local.session
def search_single_keyword(self, keyword, search_type='blog'):
"""단일 키워드 검색"""
session = self.get_session()
url = f"{BASE_URL}/{search_type}.json"
params = {'query': keyword, 'display': 20}
response = session.get(url, params=params)
if response.status_code == 200:
return {keyword: response.json()}
return {keyword: None}
def batch_search(self, keywords, search_type='blog'):
"""배치 검색 처리"""
results = {}
with concurrent.futures.ThreadPoolExecutor(max_workers=self.max_workers) as executor:
future_to_keyword = {
executor.submit(self.search_single_keyword, keyword, search_type): keyword
for keyword in keywords
}
for future in concurrent.futures.as_completed(future_to_keyword):
result = future.result()
results.update(result)
return results검색 데이터 후처리 및 분석 기법
데이터 정제 및 구조화
네이버 검색 API 활용으로 수집한 원시 데이터를 분석 가능한 형태로 변환하는 과정입니다.
import re
from datetime import datetime
import pandas as pd
class SearchDataProcessor:
def __init__(self):
self.html_tag_pattern = re.compile('<.*?>')
def clean_html_tags(self, text):
"""HTML 태그 제거"""
return re.sub(self.html_tag_pattern, '', text)
def extract_keywords(self, text, top_n=10):
"""키워드 추출 및 빈도 분석"""
from collections import Counter
import konlpy.tag import Okt
okt = Okt()
nouns = okt.nouns(text)
filtered_nouns = [noun for noun in nouns if len(noun) > 1]
return Counter(filtered_nouns).most_common(top_n)
def process_blog_data(self, raw_data):
"""블로그 데이터 전처리"""
processed_items = []
for item in raw_data:
processed_item = {
'title': self.clean_html_tags(item['title']),
'description': self.clean_html_tags(item['description']),
'blog_name': item['bloggername'],
'post_date': item['postdate'],
'url': item['link'],
'keywords': self.extract_keywords(item['description'])
}
processed_items.append(processed_item)
return pd.DataFrame(processed_items)감정 분석 및 트렌드 도출
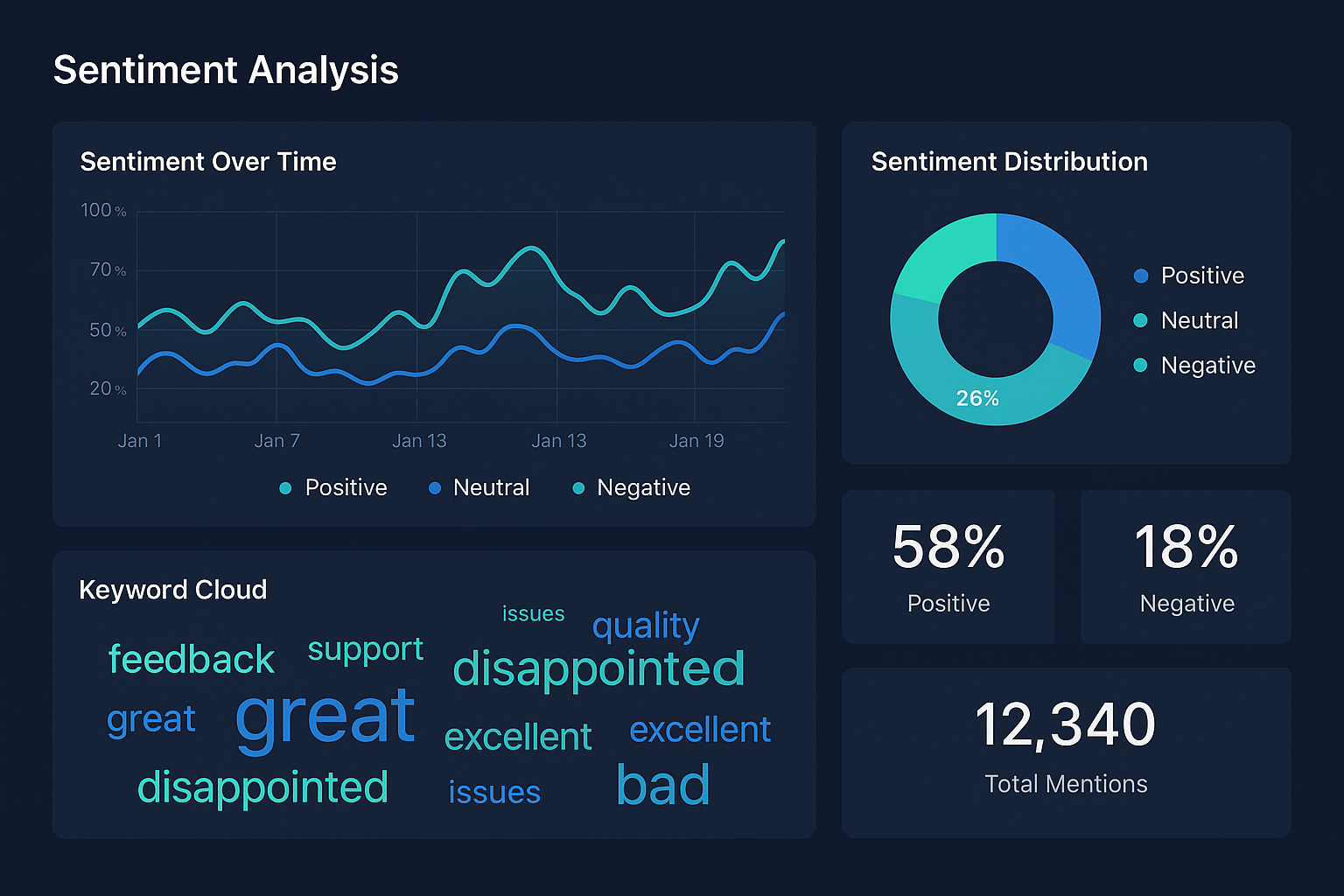
수집된 데이터의 감정을 분석하여 브랜드 이미지나 이슈의 여론을 파악합니다.
from textblob import TextBlob
import matplotlib.pyplot as plt
import seaborn as sns
class SentimentAnalyzer:
def analyze_sentiment(self, text):
"""감정 분석 수행"""
blob = TextBlob(text)
polarity = blob.sentiment.polarity
if polarity > 0.1:
return 'positive'
elif polarity < -0.1:
return 'negative'
else:
return 'neutral'
def analyze_trend(self, df, date_column='post_date'):
"""시간별 감정 트렌드 분석"""
df['sentiment'] = df['description'].apply(self.analyze_sentiment)
df[date_column] = pd.to_datetime(df[date_column])
sentiment_trend = df.groupby([df[date_column].dt.date, 'sentiment']).size().unstack(fill_value=0)
plt.figure(figsize=(12, 6))
sentiment_trend.plot(kind='bar', stacked=True)
plt.title('Sentiment Trend Over Time')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
return sentiment_trend
실무 프로젝트 케이스 스터디
경쟁사 모니터링 시스템
실제 기업에서 활용하는 경쟁사 분석을 위한 검색 자동화 시스템 구축 사례입니다.
class CompetitorMonitoringSystem:
def __init__(self, competitor_keywords, monitoring_keywords):
self.competitor_keywords = competitor_keywords
self.monitoring_keywords = monitoring_keywords
self.processor = ParallelSearchProcessor()
self.analyzer = SentimentAnalyzer()
def daily_monitoring(self):
"""일일 경쟁사 모니터링"""
results = {}
for competitor in self.competitor_keywords:
for keyword in self.monitoring_keywords:
search_query = f"{competitor} {keyword}"
blog_data = self.processor.search_single_keyword(search_query, 'blog')
news_data = self.processor.search_single_keyword(search_query, 'news')
results[f"{competitor}_{keyword}"] = {
'blog_mentions': len(blog_data[search_query]['items']) if blog_data[search_query] else 0,
'news_mentions': len(news_data[search_query]['items']) if news_data[search_query] else 0,
'timestamp': datetime.now()
}
return results
def generate_report(self, monitoring_data):
"""모니터링 리포트 생성"""
report_df = pd.DataFrame(monitoring_data).T
# 엑셀 리포트 생성
with pd.ExcelWriter('competitor_monitoring_report.xlsx') as writer:
report_df.to_excel(writer, sheet_name='Daily_Report')
return report_df콘텐츠 트렌드 분석 도구
블로거나 마케터를 위한 인기 콘텐츠 주제 발굴 도구 개발 사례입니다.
class ContentTrendAnalyzer:
def __init__(self):
self.cache = SearchAPICache()
self.processor = SearchDataProcessor()
def analyze_trending_topics(self, base_keywords, time_range_days=7):
"""트렌딩 토픽 분석"""
trending_data = {}
for keyword in base_keywords:
# 캐시 확인
cached_result = self.cache.get_cached_result('blog', keyword)
if not cached_result:
# API 호출
blog_data = self.search_and_cache(keyword)
else:
blog_data = cached_result
# 데이터 분석
processed_df = self.processor.process_blog_data(blog_data['items'])
# 키워드 빈도 분석
all_keywords = []
for keywords_list in processed_df['keywords']:
all_keywords.extend([kw[0] for kw in keywords_list])
trending_data[keyword] = Counter(all_keywords).most_common(20)
return trending_data
def search_and_cache(self, keyword):
"""검색 후 캐시 저장"""
url = f"{BASE_URL}/blog.json"
params = {'query': keyword, 'display': 100}
response = requests.get(url, headers=headers, params=params)
if response.status_code == 200:
data = response.json()
self.cache.cache_result('blog', keyword, data)
return data
return None오류 처리 및 디버깅 가이드
일반적인 오류 및 해결책
네이버 검색 API 활용 시 자주 발생하는 오류들과 해결 방법입니다.
403 Forbidden 오류
개발자 센터에 등록한 애플리케이션에서 검색 API를 사용하도록 설정하지 않았다면
'API 권한 없음'을 의미하는 403 오류가 발생할 수 있습니다.
해결책:
- 네이버 개발자 센터에서 API 설정 확인
- 검색 API가 선택되어 있는지 검증
- Client ID와 Secret 값 재확인
Rate Limit 오류 (429)
일일 호출 한도 초과 시 발생하는 오류입니다.
def handle_api_errors(func):
"""API 오류 처리 데코레이터"""
@wraps(func)
def wrapper(*args, **kwargs):
try:
return func(*args, **kwargs)
except requests.exceptions.HTTPError as e:
if e.response.status_code == 403:
print("API 권한 오류: 애플리케이션 설정을 확인하세요.")
elif e.response.status_code == 429:
print("호출 한도 초과: 잠시 후 다시 시도하세요.")
time.sleep(60) # 1분 대기
return func(*args, **kwargs)
else:
print(f"HTTP 오류: {e.response.status_code}")
except requests.exceptions.RequestException as e:
print(f"네트워크 오류: {str(e)}")
return None
return wrapper로깅 및 모니터링 시스템
안정적인 크롤러 운영을 위한 로깅 시스템 구축 방법입니다.
import logging
from logging.handlers import RotatingFileHandler
class APILogger:
def __init__(self, log_file='naver_api.log'):
self.logger = logging.getLogger('NaverSearchAPI')
self.logger.setLevel(logging.INFO)
# 파일 핸들러 설정
file_handler = RotatingFileHandler(
log_file,
maxBytes=10*1024*1024, # 10MB
backupCount=5
)
# 포맷터 설정
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
file_handler.setFormatter(formatter)
self.logger.addHandler(file_handler)
def log_api_call(self, endpoint, keyword, status_code, response_time):
"""API 호출 로그 기록"""
self.logger.info(
f"API Call - Endpoint: {endpoint}, "
f"Keyword: {keyword}, "
f"Status: {status_code}, "
f"Response Time: {response_time}ms"
)
def log_error(self, error_message, **kwargs):
"""오류 로그 기록"""
self.logger.error(f"Error: {error_message}, Details: {kwargs}")성능 최적화 고급 기법
커넥션 풀링 및 세션 관리
대량의 API 호출 시 성능을 최적화하는 고급 기법입니다.
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
class OptimizedAPIClient:
def __init__(self):
self.session = self.create_optimized_session()
def create_optimized_session(self):
"""최적화된 세션 생성"""
session = requests.Session()
# 재시도 전략 설정
retry_strategy = Retry(
total=3,
backoff_factor=1,
status_forcelist=[429, 500, 502, 503, 504],
)
# HTTP 어댑터 설정
adapter = HTTPAdapter(
pool_connections=100,
pool_maxsize=100,
max_retries=retry_strategy
)
session.mount("http://", adapter)
session.mount("https://", adapter)
session.headers.update(headers)
return session
def make_request(self, url, params):
"""최적화된 요청 실행"""
start_time = time.time()
try:
response = self.session.get(url, params=params, timeout=30)
response.raise_for_status()
response_time = (time.time() - start_time) * 1000
return response.json(), response_time
except requests.exceptions.RequestException as e:
print(f"Request failed: {str(e)}")
return None, None메모리 최적화 및 가비지 컬렉션
대용량 데이터 처리 시 메모리 효율성을 높이는 방법입니다.
import gc
import psutil
import os
class MemoryOptimizedProcessor:
def __init__(self, memory_limit_mb=1000):
self.memory_limit = memory_limit_mb * 1024 * 1024 # MB to bytes
def check_memory_usage(self):
"""메모리 사용량 확인"""
process = psutil.Process(os.getpid())
memory_info = process.memory_info()
return memory_info.rss
def process_large_dataset(self, keywords, batch_size=100):
"""대용량 데이터셋 배치 처리"""
results = []
for i in range(0, len(keywords), batch_size):
batch = keywords[i:i + batch_size]
# 배치 처리
batch_results = self.process_batch(batch)
results.extend(batch_results)
# 메모리 사용량 확인
if self.check_memory_usage() > self.memory_limit:
gc.collect() # 가비지 컬렉션 강제 실행
print(f"Memory cleanup performed at batch {i//batch_size + 1}")
return results
def process_batch(self, batch):
"""단일 배치 처리"""
# 배치 처리 로직 구현
batch_results = []
for keyword in batch:
# API 호출 및 데이터 처리
result = self.search_and_process(keyword)
if result:
batch_results.append(result)
return batch_results고급 활용 사례: 실시간 모니터링 대시보드
WebSocket을 활용한 실시간 데이터 스트리밍
실시간으로 검색 결과를 모니터링할 수 있는 대시보드 구축 방법입니다.
import asyncio
import websockets
import json
from datetime import datetime
class RealTimeMonitoringDashboard:
def __init__(self):
self.clients = set()
self.api_client = OptimizedAPIClient()
async def register_client(self, websocket, path):
"""클라이언트 등록"""
self.clients.add(websocket)
try:
await websocket.wait_closed()
finally:
self.clients.remove(websocket)
async def broadcast_data(self, data):
"""모든 클라이언트에게 데이터 브로드캐스트"""
if self.clients:
message = json.dumps({
'timestamp': datetime.now().isoformat(),
'data': data
})
await asyncio.gather(
*[client.send(message) for client in self.clients],
return_exceptions=True
)
async def monitor_keywords(self, keywords, interval=300):
"""키워드 실시간 모니터링"""
while True:
monitoring_data = {}
for keyword in keywords:
# 뉴스 검색
news_data, _ = self.api_client.make_request(
f"{BASE_URL}/news.json",
{'query': keyword, 'display': 10, 'sort': 'date'}
)
if news_data:
monitoring_data[keyword] = {
'news_count': len(news_data['items']),
'latest_news': news_data['items'][:3] if news_data['items'] else []
}
# 클라이언트들에게 데이터 전송
await self.broadcast_data(monitoring_data)
# 지정된 간격만큼 대기
await asyncio.sleep(interval)
def start_dashboard(self, keywords, port=8765):
"""대시보드 서버 시작"""
start_server = websockets.serve(self.register_client, "localhost", port)
# 모니터링 태스크와 서버를 동시에 실행
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.gather(
start_server,
self.monitor_keywords(keywords)
))대시보드 프론트엔드 (HTML/JavaScript)
<!DOCTYPE html>
<html>
<head>
<title>실시간 검색 모니터링 대시보드</title>
<script src="https://cdn.jsdelivr.net/npm/chart.js"></script>
<style>
.dashboard { display: grid; grid-template-columns: 1fr 1fr; gap: 20px; }
.card { border: 1px solid #ddd; padding: 20px; border-radius: 8px; }
.news-item { margin: 10px 0; padding: 10px; background: #f5f5f5; }
</style>
</head>
<body>
<div class="dashboard">
<div class="card">
<h3>실시간 검색량</h3>
<canvas id="searchChart"></canvas>
</div>
<div class="card">
<h3>최신 뉴스</h3>
<div id="newsContainer"></div>
</div>
</div>
<script>
const socket = new WebSocket('ws://localhost:8765');
const chart = new Chart(document.getElementById('searchChart'), {
type: 'line',
data: {
labels: [],
datasets: [{
label: '검색량',
data: [],
borderColor: 'rgb(75, 192, 192)',
tension: 0.1
}]
},
options: {
responsive: true,
scales: {
y: { beginAtZero: true }
}
}
});
socket.onmessage = function(event) {
const data = JSON.parse(event.data);
updateChart(data);
updateNews(data);
};
function updateChart(data) {
const timestamp = new Date(data.timestamp).toLocaleTimeString();
chart.data.labels.push(timestamp);
let totalCount = 0;
Object.values(data.data).forEach(item => {
totalCount += item.news_count || 0;
});
chart.data.datasets[0].data.push(totalCount);
chart.update();
}
function updateNews(data) {
const newsContainer = document.getElementById('newsContainer');
newsContainer.innerHTML = '';
Object.entries(data.data).forEach(([keyword, info]) => {
if (info.latest_news && info.latest_news.length > 0) {
const keywordDiv = document.createElement('div');
keywordDiv.innerHTML = `<h4>${keyword}</h4>`;
info.latest_news.forEach(news => {
const newsDiv = document.createElement('div');
newsDiv.className = 'news-item';
newsDiv.innerHTML = `
<strong>${news.title}</strong><br>
<small>${news.pubDate}</small>
`;
keywordDiv.appendChild(newsDiv);
});
newsContainer.appendChild(keywordDiv);
}
});
}
</script>
</body>
</html>법적 고려사항 및 윤리적 사용
이용약관 준수
네이버 검색 API 활용 시 반드시 지켜야 할 법적 요구사항들입니다.
- 일일 호출 한도 25,000회 엄수
- 상업적 이용 시 별도 협의 필요
- 개인정보 보호 관련 법규 준수
- 로봇 배제 표준(robots.txt) 존중
윤리적 크롤링 가이드라인
class EthicalCrawlingManager:
def __init__(self):
self.request_delay = 1.0 # 1초 딜레이
self.user_agent = "Ethical Research Bot 1.0"
def respectful_crawling(self, urls, delay=None):
"""윤리적 크롤링 실행"""
if delay is None:
delay = self.request_delay
results = []
for url in urls:
# 딜레이 적용
time.sleep(delay)
# User-Agent 설정
headers_with_ua = {**headers, 'User-Agent': self.user_agent}
try:
response = requests.get(url, headers=headers_with_ua)
results.append(response)
except Exception as e:
print(f"윤리적 크롤링 오류: {str(e)}")
return results
def check_robots_txt(self, domain):
"""robots.txt 확인"""
robots_url = f"{domain}/robots.txt"
try:
response = requests.get(robots_url)
if response.status_code == 200:
return response.text
except:
pass
return None성능 벤치마크 및 측정
API 응답 시간 측정
검색 자동화 시스템의 성능을 정확히 측정하는 방법입니다.
import statistics
from contextlib import contextmanager
class PerformanceBenchmark:
def __init__(self):
self.response_times = []
self.success_count = 0
self.error_count = 0
@contextmanager
def measure_time(self):
"""시간 측정 컨텍스트 매니저"""
start_time = time.time()
try:
yield
self.success_count += 1
except Exception as e:
self.error_count += 1
raise
finally:
elapsed_time = (time.time() - start_time) * 1000
self.response_times.append(elapsed_time)
def benchmark_api_performance(self, keywords, iterations=10):
"""API 성능 벤치마크"""
total_calls = len(keywords) * iterations
print(f"성능 테스트 시작: {total_calls}회 호출")
for i in range(iterations):
for keyword in keywords:
with self.measure_time():
url = f"{BASE_URL}/blog.json"
params = {'query': keyword, 'display': 10}
response = requests.get(url, headers=headers, params=params)
if response.status_code != 200:
raise Exception(f"API 호출 실패: {response.status_code}")
self.print_performance_report()
def print_performance_report(self):
"""성능 리포트 출력"""
if not self.response_times:
print("측정된 데이터가 없습니다.")
return
avg_time = statistics.mean(self.response_times)
median_time = statistics.median(self.response_times)
min_time = min(self.response_times)
max_time = max(self.response_times)
print("\n=== 성능 벤치마크 결과 ===")
print(f"총 요청 수: {len(self.response_times)}")
print(f"성공: {self.success_count}, 실패: {self.error_count}")
print(f"평균 응답 시간: {avg_time:.2f}ms")
print(f"중간값 응답 시간: {median_time:.2f}ms")
print(f"최소 응답 시간: {min_time:.2f}ms")
print(f"최대 응답 시간: {max_time:.2f}ms")
print(f"성공률: {(self.success_count / len(self.response_times)) * 100:.2f}%")마이크로서비스 아키텍처 구현
Docker 컨테이너화
크롤러 시스템을 컨테이너화하여 확장성과 관리성을 높이는 방법입니다.
# Dockerfile
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["python", "app.py"]# docker-compose.yml
version: '3.8'
services:
naver-api-service:
build: .
ports:
- "8000:8000"
environment:
- NAVER_CLIENT_ID=${NAVER_CLIENT_ID}
- NAVER_CLIENT_SECRET=${NAVER_CLIENT_SECRET}
- REDIS_URL=redis://redis:6379
depends_on:
- redis
- postgres
redis:
image: redis:6-alpine
ports:
- "6379:6379"
postgres:
image: postgres:13
environment:
- POSTGRES_DB=naver_search
- POSTGRES_USER=admin
- POSTGRES_PASSWORD=password
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
volumes:
postgres_data:FastAPI를 활용한 API 서버 구축
from fastapi import FastAPI, HTTPException, BackgroundTasks
from pydantic import BaseModel
from typing import List, Optional
import uvicorn
app = FastAPI(title="네이버 검색 API 서비스", version="1.0.0")
class SearchRequest(BaseModel):
keywords: List[str]
search_type: str = "blog"
max_results: int = 10
class SearchResponse(BaseModel):
keyword: str
results: List[dict]
total_count: int
processing_time: float
@app.post("/search/batch", response_model=List[SearchResponse])
async def batch_search(request: SearchRequest, background_tasks: BackgroundTasks):
"""배치 검색 엔드포인트"""
try:
processor = ParallelSearchProcessor()
start_time = time.time()
results = processor.batch_search(
request.keywords,
request.search_type
)
processing_time = time.time() - start_time
response_data = []
for keyword, data in results.items():
if data and 'items' in data:
response_data.append(SearchResponse(
keyword=keyword,
results=data['items'][:request.max_results],
total_count=len(data['items']),
processing_time=processing_time
))
# 백그라운드에서 결과 저장
background_tasks.add_task(save_search_results, results)
return response_data
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/health")
async def health_check():
"""헬스 체크 엔드포인트"""
return {"status": "healthy", "timestamp": datetime.now().isoformat()}
async def save_search_results(results):
"""검색 결과를 데이터베이스에 저장"""
# 데이터베이스 저장 로직 구현
pass
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)미래 확장 가능성 및 로드맵
AI/ML 통합 방안
네이버 검색 API 활용과 머신러닝을 결합한 고도화 방안입니다.
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from transformers import pipeline
class AIEnhancedSearchAnalyzer:
def __init__(self):
self.vectorizer = TfidfVectorizer(max_features=1000, stop_words='english')
self.sentiment_analyzer = pipeline("sentiment-analysis")
def cluster_search_results(self, search_results, n_clusters=5):
"""검색 결과 클러스터링"""
texts = [item['description'] for item in search_results]
# TF-IDF 벡터화
tfidf_matrix = self.vectorizer.fit_transform(texts)
# K-means 클러스터링
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
clusters = kmeans.fit_predict(tfidf_matrix)
# 클러스터별 결과 그룹화
clustered_results = {}
for i, cluster_id in enumerate(clusters):
if cluster_id not in clustered_results:
clustered_results[cluster_id] = []
clustered_results[cluster_id].append(search_results[i])
return clustered_results
def analyze_sentiment_trends(self, search_results):
"""감정 분석 트렌드"""
sentiments = []
for item in search_results:
text = item['title'] + " " + item['description']
sentiment = self.sentiment_analyzer(text[:512])[0] # 토큰 제한
sentiments.append({
'text': text,
'sentiment': sentiment['label'],
'confidence': sentiment['score'],
'date': item.get('pubDate', '')
})
return sentiments
def predict_trending_keywords(self, historical_data):
"""트렌딩 키워드 예측"""
# 시계열 분석을 통한 키워드 트렌드 예측
# 실제 구현 시 LSTM 등의 딥러닝 모델 활용 가능
pass블록체인 기반 데이터 무결성
수집된 데이터의 무결성을 보장하기 위한 블록체인 활용 방안입니다.
import hashlib
import json
from datetime import datetime
class BlockchainDataIntegrity:
def __init__(self):
self.chain = []
self.create_genesis_block()
def create_genesis_block(self):
"""제네시스 블록 생성"""
genesis_block = {
'index': 0,
'timestamp': datetime.now().isoformat(),
'data': 'Genesis Block',
'previous_hash': '0',
'hash': self.calculate_hash(0, datetime.now().isoformat(), 'Genesis Block', '0')
}
self.chain.append(genesis_block)
def calculate_hash(self, index, timestamp, data, previous_hash):
"""블록 해시 계산"""
value = str(index) + str(timestamp) + str(data) + str(previous_hash)
return hashlib.sha256(value.encode('utf-8')).hexdigest()
def add_search_data_block(self, search_data):
"""검색 데이터 블록 추가"""
previous_block = self.chain[-1]
new_index = previous_block['index'] + 1
new_timestamp = datetime.now().isoformat()
new_hash = self.calculate_hash(
new_index,
new_timestamp,
search_data,
previous_block['hash']
)
new_block = {
'index': new_index,
'timestamp': new_timestamp,
'data': search_data,
'previous_hash': previous_block['hash'],
'hash': new_hash
}
self.chain.append(new_block)
return new_block
def verify_chain_integrity(self):
"""체인 무결성 검증"""
for i in range(1, len(self.chain)):
current_block = self.chain[i]
previous_block = self.chain[i-1]
# 현재 블록의 해시 검증
calculated_hash = self.calculate_hash(
current_block['index'],
current_block['timestamp'],
current_block['data'],
current_block['previous_hash']
)
if current_block['hash'] != calculated_hash:
return False
# 이전 블록과의 연결 검증
if current_block['previous_hash'] != previous_block['hash']:
return False
return True커뮤니티와 생태계
오픈소스 기여 방안
검색 자동화 분야의 오픈소스 프로젝트에 기여하는 방법입니다.
추천 오픈소스 프로젝트
- Scrapy - 파이썬 크롤링 프레임워크
- Selenium - 웹 브라우저 자동화
- BeautifulSoup - HTML/XML 파싱 라이브러리
- Requests - HTTP 라이브러리
기여 가이드라인
class OpenSourceContributor:
"""오픈소스 기여를 위한 가이드라인"""
def __init__(self):
self.contribution_types = [
"버그 수정",
"새로운 기능 개발",
"문서화 개선",
"테스트 코드 작성",
"성능 최적화"
]
def create_pull_request_template(self):
"""풀 리퀘스트 템플릿"""
template = """
## 변경 사항 요약
- [변경 내용을 간단히 설명]
## 관련 이슈
- Fixes #[이슈 번호]
## 테스트 방법
- [테스트 방법 설명]
## 체크리스트
- [ ] 코드 스타일 가이드 준수
- [ ] 테스트 코드 작성
- [ ] 문서 업데이트
- [ ] 하위 호환성 확인
"""
return template
def best_practices(self):
"""기여 모범 사례"""
practices = [
"작은 단위로 커밋하기",
"명확한 커밋 메시지 작성",
"코드 리뷰 적극 참여",
"이슈 트래커 활용",
"커뮤니티 가이드라인 준수"
]
return practices결론 및 향후 전망
네이버 검색 API 활용은 현대 웹 개발에서 필수적인 기술로 자리잡았습니다.
본 가이드에서 다룬 검색 자동화 기법들은 단순한 데이터 수집을 넘어서 지능적인 정보 분석 시스템 구축의 기반이 됩니다.
핵심 포인트 요약
- 효율적인 API 활용: Rate limiting과 캐싱을 통한 최적화
- 확장 가능한 아키텍처: 마이크로서비스와 컨테이너화
- 윤리적 크롤링: 법적 요구사항과 윤리적 가이드라인 준수
- 성능 모니터링: 실시간 대시보드와 벤치마킹
- AI 통합: 머신러닝을 활용한 고도화 방안
미래 기술 트렌드
- 실시간 스트리밍: WebSocket 기반 실시간 데이터 처리
- 엣지 컴퓨팅: CDN을 활용한 분산 처리
- AutoML: 자동화된 머신러닝 파이프라인
- GraphQL: 효율적인 데이터 쿼리 인터페이스
크롤러 기술의 발전과 함께 API 활용 방식도 지속적으로 진화하고 있습니다.
앞으로는 더욱 지능적이고 효율적인 데이터 수집 시스템이 주목받을 것으로 예상됩니다.
참고 자료 및 추가 학습 링크
공식 문서
기술 문서
학습 리소스
이 가이드를 통해 네이버 검색 API 활용의 전문가가 되어 효율적인 검색 자동화 시스템을 구축하시기 바랍니다.
지속적인 학습과 실습을 통해 더욱 발전된 크롤러 시스템을 개발하시길 응원합니다.
'유용한툴 및 사이트' 카테고리의 다른 글
| PlanetScale vs Supabase: 2025년 MySQL & PostgreSQL 클라우드 DB 서비스 완전 비교 (0) | 2025.07.20 |
|---|---|
| Postman vs Insomnia: 2025년 최고의 API 테스트 툴 비교 및 선택 가이드 (0) | 2025.07.20 |
| 실시간 AI 이미지 생성 API 무료/유료 서비스 비교: 2025년 완벽 가이드 (0) | 2025.06.24 |
| Mermaid로 아키텍처 다이어그램 자동화하기: 마크다운으로 그리는 효율적인 아키텍처 문서 (0) | 2025.06.23 |
| 개발자용 생산성 앱 비교: Notion vs Obsidian vs Logseq - 2025년 완벽 가이드 (0) | 2025.05.29 |



