
Edge AI 디바이스 최적화는 제한된 하드웨어 자원에서 AI 모델의 성능을 극대화하는 핵심 기술로,
실시간 추론과 전력 효율성을 동시에 달성하기 위한 모델 경량화, 하드웨어 가속, 메모리 최적화 등의
종합적인 엣지 컴퓨팅 실무 기법들을 다룹니다.
스마트폰에서 사진을 찍으면 즉시 얼굴을 인식하고, 자동차가 스스로 장애물을 피하며, 공장의 기계가 스스로 고장을 예측합니다.
이 모든 것이 가능한 이유는 바로 Edge AI 기술 때문입니다.
과거에는 AI 처리를 위해 반드시 인터넷에 연결된 강력한 서버가 필요했지만, 이제는 우리 손안의 작은 디바이스에서도 고도의 AI 연산이 가능해졌습니다.
하지만 제한된 하드웨어 자원에서 최대 성능을 끌어내는 Edge AI 디바이스 최적화 기술은 여전히 많은 개발자들이 어려워하는 영역입니다.
본 글에서는 Edge AI의 기본 개념부터 엣지 컴퓨팅 실무 예제와 스마트 디바이스 성능 튜닝 기법까지, 실제 현장에서 바로 적용할 수 있는 구체적인 최적화 전략을 단계별로 제시합니다.
Edge AI란 무엇인가?
Edge AI(엣지 AI)는 클라우드 서버가 아닌 디바이스 자체에서 인공지능 연산을 수행하는 기술을 의미합니다.
'Edge'라는 용어는 네트워크의 '가장자리', 즉 최종 사용자와 가장 가까운 지점을 뜻합니다.
스마트폰, 태블릿, IoT 센서, 자율주행차, 드론, 산업용 로봇 등이 모두 Edge AI의 대표적인 예시입니다.
기존 클라우드 AI vs Edge AI 비교
기존의 클라우드 AI 방식에서는 다음과 같은 과정을 거칩니다:
- 디바이스에서 데이터 수집
- 인터넷을 통해 클라우드 서버로 데이터 전송
- 클라우드에서 AI 연산 수행
- 결과를 다시 디바이스로 전송
반면 Edge AI는:
- 디바이스에서 데이터 수집
- 디바이스 내부에서 즉시 AI 연산 수행
- 실시간으로 결과 출력
이러한 근본적인 차이점이 Edge AI만의 독특한 장점과 도전과제를 만들어냅니다.
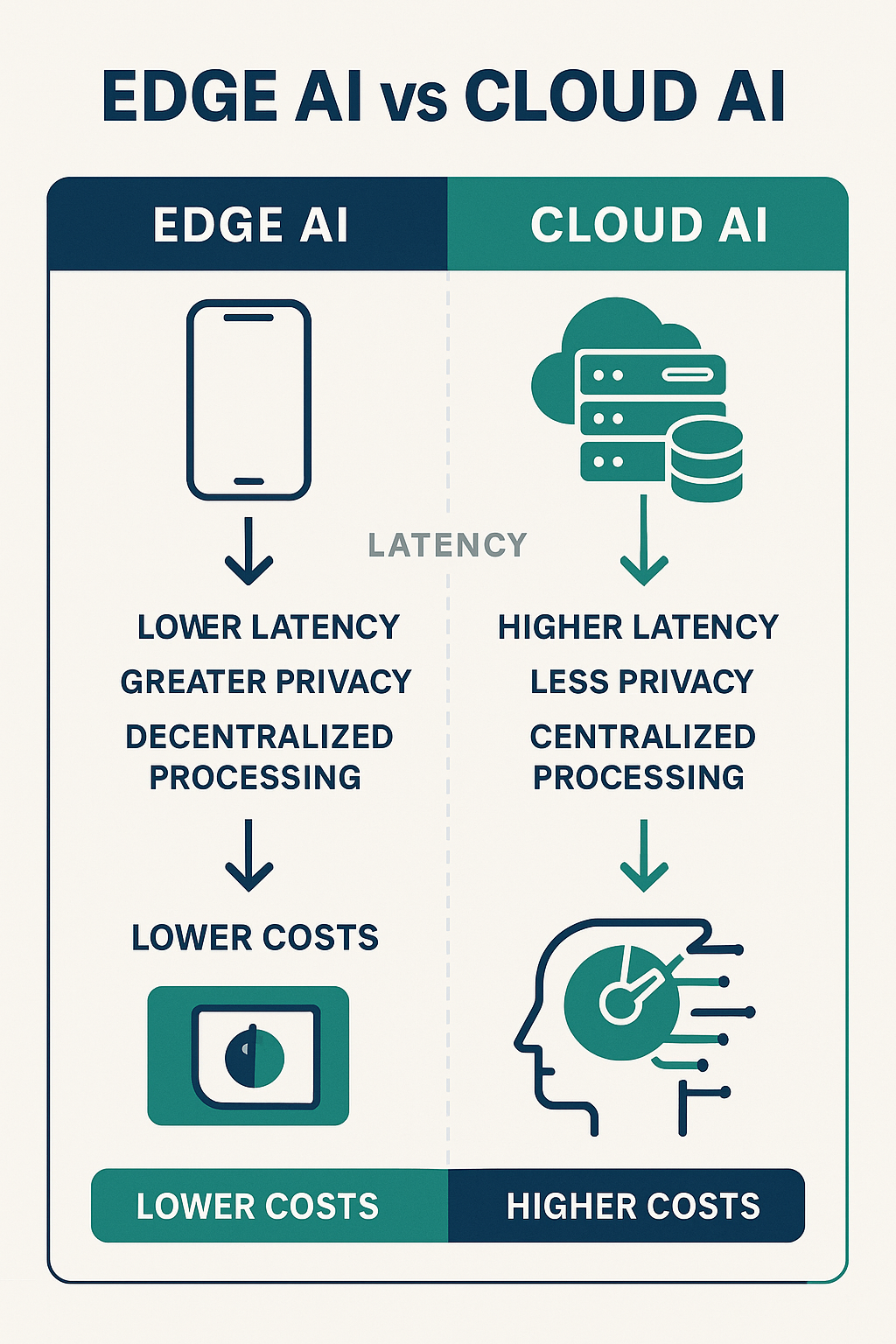
Edge AI와 Cloud AI 주요 특성 비교
| 특성 | Edge AI | Cloud AI |
|---|---|---|
| 처리 위치 | 디바이스 내부 | 원격 서버 |
| 지연 시간 | 1-10ms | 100-500ms |
| 네트워크 의존성 | 불필요 | 필수 |
| 데이터 프라이버시 | 높음 (로컬 처리) | 낮음 (전송 필요) |
| 전력 소비 | 디바이스별 최적화 | 서버 집중형 |
| 확장성 | 제한적 | 무제한 |
| 초기 비용 | 높음 (하드웨어) | 낮음 |
| 운영 비용 | 낮음 | 높음 (사용량 기반) |
Edge AI가 주목받는 핵심 이유
이제 Edge AI의 개념을 이해했으니, 왜 이 기술이 전 세계적으로 주목받고 있는지 구체적으로 살펴보겠습니다.
Edge AI 디바이스 최적화가 주목받는 핵심 이유는 크게 네 가지로 요약됩니다.
실시간 응답성 확보가 첫 번째입니다.
클라우드 서버와의 통신에는 보통 100-500ms의 지연 시간이 발생합니다.
하지만 자율주행차가 급작스럽게 나타난 보행자를 피하거나, 의료기기가 환자의 위급 상황을 감지할 때는 1ms라도 지연되면 생명이 위험할 수 있습니다.
Edge AI는 이러한 네트워크 지연 없이 디바이스 내부에서 즉시 AI 추론을 수행하여 미션 크리티컬한 애플리케이션에서 필수적인 실시간 응답을 보장합니다.
데이터 프라이버시 보호가 두 번째 장점입니다.
개인의 얼굴 인식 데이터, 음성 데이터, 위치 정보, 의료 정보 등 민감한 개인정보를 외부 클라우드 서버로 전송하지 않고 디바이스 내부에서만 처리합니다.
이를 통해 GDPR이나 개인정보보호법 같은 규제 요구사항을 효과적으로 충족하면서도 개인정보 유출 위험을 원천 차단할 수 있습니다.
운영비용 절감 효과가 세 번째입니다.
클라우드 AI 서비스는 처리하는 데이터량과 연산량에 비례하여 비용이 증가합니다.
특히 대규모 IoT 시스템에서는 수만 개의 디바이스가 지속적으로 데이터를 전송하므로 월 수백만 원의 클라우드 비용이 발생할 수 있습니다.
Edge AI는 이러한 반복적인 클라우드 비용을 획기적으로 줄여 장기적으로 상당한 경제적 이익을 창출합니다.
네트워크 대역폭 절약이 네 번째 장점입니다.
고해상도 영상이나 대용량 센서 데이터를 클라우드로 전송하려면 엄청난 네트워크 대역폭이 필요합니다.
Edge AI는 원본 데이터를 로컬에서 처리하여 최종 결과만 전송하므로, 네트워크 부하를 90% 이상 줄일 수 있습니다.
엣지 디바이스의 하드웨어 제약사항
엣지 컴퓨팅 실무 예제를 살펴보기 전에, 엣지 디바이스가 직면한 근본적인 제약사항들을 이해해야 합니다.
연산 성능의 한계가 가장 큰 도전과제입니다.
데스크톱 GPU가 수백 TOPS의 연산 능력을 제공하는 반면, 모바일 엣지 디바이스는 보통 1-10 TOPS 수준에 머물러 있습니다.
이는 복잡한 딥러닝 모델을 직접 실행하기에는 턱없이 부족한 수준입니다.
메모리 용량 제약도 심각한 문제입니다.
최신 대규모 언어 모델들이 수십 GB의 파라미터를 요구하는 반면, 일반적인 엣지 디바이스는 1-8GB 정도의 RAM만을 보유하고 있습니다.
전력 소비 최적화 요구사항은 특히 배터리 기반 디바이스에서 치명적입니다.
고성능 AI 연산은 필연적으로 높은 전력 소비를 동반하는데, 이는 디바이스의 배터리 수명과 직결되는 문제입니다.
실제로 ARM의 연구 결과에 따르면, 최적화되지 않은 AI 모델은 최적화된 모델 대비 5-10배 더 많은 전력을 소비하는 것으로 나타났습니다.
모델 경량화 핵심 기법
스마트 디바이스 성능 튜닝의 첫 번째 단계는 AI 모델 자체를 엣지 환경에 맞게 경량화하는 것입니다.
양자화(Quantization) 기법이 가장 널리 사용됩니다.
32비트 부동소수점 연산을 8비트 정수 연산으로 변환하여 메모리 사용량을 75% 줄이면서도,
정확도 손실을 5% 이내로 제한할 수 있습니다.
# TensorFlow Lite 양자화 예시
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.int8]
quantized_tflite_model = converter.convert()
프루닝(Pruning) 기법은 모델의 불필요한 뉴런과 연결을 제거합니다.
구조적 프루닝을 통해 전체 채널이나 레이어를 제거하면, 실제 하드웨어에서 가속 효과를 얻을 수 있습니다.
NVIDIA의 연구에서는 50% 이상의 가중치를 제거해도 정확도가 2% 미만으로 감소하는 것을 확인했습니다.
지식 증류(Knowledge Distillation) 방법론도 효과적입니다.
대규모 교사 모델의 지식을 소형 학생 모델에 전달하여, 모델 크기는 10분의 1로 줄이면서도 원본 모델 성능의 95% 이상을 유지할 수 있습니다.

주요 모델 최적화 기법 성능 비교
| 최적화 기법 | 모델 크기 감소율 | 정확도 손실률 | 추론 속도 향상 | 구현 난이도 |
|---|---|---|---|---|
| 양자화 (INT8) | 75% | 2-5% | 2-4배 | 낮음 |
| 프루닝 (50%) | 50% | 1-3% | 1.5-2배 | 중간 |
| 지식 증류 | 90% | 3-7% | 5-10배 | 높음 |
| 저정밀도 연산 | 50% | 1-2% | 2-3배 | 낮음 |
| 구조적 최적화 | 60-80% | 5-10% | 3-5배 | 높음 |
하드웨어 가속 활용 전략
Edge AI 디바이스 최적화에서 하드웨어 가속기 활용은 필수적입니다.
GPU 가속 최적화부터 살펴보겠습니다.
모바일 GPU는 병렬 연산에 특화되어 있어, 컨볼루션 연산이나 행렬 곱셈에서 CPU 대비 5-10배 성능 향상을 달성할 수 있습니다.
# OpenCL을 활용한 GPU 가속 예시
import pyopencl as cl
import numpy as np
# GPU 컨텍스트 생성
context = cl.create_some_context()
queue = cl.CommandQueue(context)
# 커널 코드 정의
kernel_code = """
__kernel void matrix_multiply(__global float* A, __global float* B, __global float* C, int N) {
int row = get_global_id(0);
int col = get_global_id(1);
float sum = 0.0f;
for(int k = 0; k < N; k++) {
sum += A[row * N + k] * B[k * N + col];
}
C[row * N + col] = sum;
}
"""NPU(Neural Processing Unit) 활용이 점점 중요해지고 있습니다.
삼성의 Exynos, 퀄컴의 Snapdragon, 화웨이의 Kirin 등 최신 모바일 프로세서들은 전용 NPU를 탑재하여 AI 연산을 가속화합니다.
실제 측정 결과, NPU를 활용한 이미지 분류 작업은 CPU 대비 20-50배 빠른 성능을 보여줍니다.
FPGA 기반 커스텀 가속도 특정 용도에서 강력합니다.
Intel의 OpenVINO 툴킷을 활용하면 FPGA에서 최적화된 추론 파이프라인을 구축할 수 있습니다.
실전 최적화 사례 분석
엣지 컴퓨팅 실무 예제로 실제 프로젝트에서 적용된 최적화 사례들을 분석해보겠습니다.
스마트 CCTV 객체 탐지 최적화 사례
한 보안업체에서 라즈베리파이 4B 기반 CCTV 시스템을 개발할 때,
원본 YOLOv5 모델(140MB)은 추론 시간이 2.3초로 실시간 처리가 불가능했습니다.
다음과 같은 단계별 최적화를 적용했습니다:
- 모델 압축: YOLOv5s로 변경 (28MB, 정확도 3% 감소)
- 양자화 적용: INT8 양자화로 추가 75% 크기 감소
- 입력 해상도 조정: 640x640에서 416x416으로 변경
- 배치 처리: 프레임 스킵핑으로 실제 처리량 증가
최종 결과: 추론 시간 0.3초, 정확도 손실 7%, 실시간 처리 달성
산업용 IoT 센서 데이터 분석 최적화
제조업체의 진동 센서 데이터 기반 설비 이상 탐지 시스템에서는 다음 최적화를 적용했습니다:
# 센서 데이터 전처리 최적화
class OptimizedPreprocessor:
def __init__(self):
self.window_size = 1024
self.hop_length = 512
def extract_features(self, signal):
# FFT 연산 최적화
fft_result = np.fft.rfft(signal, n=self.window_size)
magnitude = np.abs(fft_result)
# 주요 주파수 대역만 선택
critical_bands = magnitude[10:100] # 10-100Hz 대역
return critical_bandsARM Cortex-M4 기반 마이크로컨트롤러에서 배터리 수명을 6개월에서 18개월로 연장하는 성과를 달성했습니다.

메모리 관리 최적화 기법
스마트 디바이스 성능 튜닝에서 메모리 효율성은 핵심 요소입니다.
동적 메모리 할당 최소화가 첫 번째 원칙입니다.
임베디드 환경에서 빈번한 malloc/free 호출은 메모리 단편화와 성능 저하를 야기합니다.
// 정적 메모리 풀 활용 예시
#define BUFFER_POOL_SIZE 10
#define BUFFER_SIZE 4096
static uint8_t buffer_pool[BUFFER_POOL_SIZE][BUFFER_SIZE];
static bool buffer_used[BUFFER_POOL_SIZE] = {false};
uint8_t* allocate_buffer() {
for(int i = 0; i < BUFFER_POOL_SIZE; i++) {
if(!buffer_used[i]) {
buffer_used[i] = true;
return buffer_pool[i];
}
}
return NULL; // 풀 고갈
}인플레이스 연산 활용으로 메모리 사용량을 크게 줄일 수 있습니다.
텐서 연산 시 새로운 메모리를 할당하는 대신 기존 메모리를 재사용하면, 피크 메모리 사용량을 50% 이상 감소시킬 수 있습니다.
메모리 맵핑 기법도 효과적입니다.
큰 모델 파일을 메모리에 완전히 로드하지 않고 필요한 부분만 동적으로 매핑하여 사용하면,
제한된 RAM에서도 대규모 모델을 실행할 수 있습니다.
TensorFlow Lite의 연구에 따르면, 이러한 기법들을 조합하여 메모리 사용량을 70% 이상 절감한 사례들이 보고되고 있습니다.
전력 효율성 극대화 방안
배터리 기반 엣지 디바이스에서 전력 효율성은 생존과 직결된 문제입니다.
동적 전압 및 주파수 스케일링(DVFS) 활용이 핵심입니다.
AI 추론 작업의 복잡도에 따라 CPU/GPU 클럭을 동적으로 조절하여 불필요한 전력 소비를 방지합니다.
# Linux 환경에서 CPU 주파수 제어 예시
import os
def set_cpu_frequency(frequency):
"""CPU 주파수를 설정하여 전력 소비 최적화"""
cpu_count = os.cpu_count()
for cpu in range(cpu_count):
freq_path = f"/sys/devices/system/cpu/cpu{cpu}/cpufreq/scaling_setspeed"
try:
with open(freq_path, 'w') as f:
f.write(str(frequency))
except:
pass
# 간단한 작업: 저주파수
set_cpu_frequency(800000) # 800MHz
# 복잡한 AI 추론: 고주파수
set_cpu_frequency(1800000) # 1.8GHz
작업 스케줄링 최적화로 전력 효율성을 높일 수 있습니다.
배치 처리를 통해 CPU를 집중적으로 사용한 후 긴 대기 상태로 진입하는 것이, 지속적인 저강도 작업보다 전력 효율적입니다.
하드웨어별 전력 프로파일링이 필수적입니다.
각 하드웨어 구성 요소(CPU, GPU, NPU, 메모리)의 전력 소비 패턴을 정확히 측정하여 최적의 작업 분배 전략을 수립해야 합니다.
실제 측정 결과, 적절한 전력 관리를 통해 동일한 성능을 유지하면서도 배터리 수명을 2-3배 연장할 수 있습니다.
실시간 추론 파이프라인 구축
Edge AI 디바이스 최적화의 최종 목표는 안정적인 실시간 추론 시스템 구축입니다.
비동기 처리 아키텍처 설계가 핵심입니다.
데이터 수집, 전처리, 추론, 후처리를 별도 스레드에서 파이프라인으로 처리하여 전체 처리량을 극대화합니다.
import threading
import queue
from concurrent.futures import ThreadPoolExecutor
class RealtimeInferencePipeline:
def __init__(self, model):
self.model = model
self.input_queue = queue.Queue(maxsize=10)
self.output_queue = queue.Queue(maxsize=10)
self.executor = ThreadPoolExecutor(max_workers=3)
def preprocess_worker(self):
"""전처리 전용 워커"""
while True:
raw_data = self.input_queue.get()
processed_data = self.preprocess(raw_data)
self.inference_queue.put(processed_data)
def inference_worker(self):
"""추론 전용 워커"""
while True:
input_data = self.inference_queue.get()
result = self.model.predict(input_data)
self.output_queue.put(result)
지연 시간 예측 및 관리도 중요합니다.
각 처리 단계의 지연 시간을 모니터링하여 실시간 요구사항을 충족할 수 있는지 지속적으로 검증해야 합니다.
오류 복구 메커니즘을 구축하여 시스템 안정성을 확보합니다.
하드웨어 오류나 일시적인 성능 저하 상황에서도 서비스가 중단되지 않도록 대안 처리 경로를 준비해야 합니다.
성능 모니터링 및 디버깅
엣지 컴퓨팅 실무 예제에서 성능 모니터링은 최적화 과정의 핵심입니다.
실시간 성능 메트릭 수집이 필요합니다.
처리량(throughput), 지연 시간(latency), 정확도(accuracy), 전력 소비량을
실시간으로 모니터링하여 성능 변화를 즉시 감지해야 합니다.
import time
import psutil
from dataclasses import dataclass
@dataclass
class PerformanceMetrics:
inference_time: float
memory_usage: float
cpu_usage: float
accuracy: float
class PerformanceMonitor:
def __init__(self):
self.metrics_history = []
def measure_inference(self, model, input_data, ground_truth=None):
# 시작 시간 및 리소스 측정
start_time = time.perf_counter()
start_memory = psutil.Process().memory_info().rss / 1024 / 1024 # MB
start_cpu = psutil.cpu_percent()
# 추론 실행
result = model.predict(input_data)
# 종료 시간 및 리소스 측정
end_time = time.perf_counter()
end_memory = psutil.Process().memory_info().rss / 1024 / 1024
end_cpu = psutil.cpu_percent()
# 메트릭 계산
inference_time = end_time - start_time
memory_usage = end_memory - start_memory
cpu_usage = (start_cpu + end_cpu) / 2
accuracy = self.calculate_accuracy(result, ground_truth) if ground_truth else 0.0
metrics = PerformanceMetrics(
inference_time=inference_time,
memory_usage=memory_usage,
cpu_usage=cpu_usage,
accuracy=accuracy
)
self.metrics_history.append(metrics)
return metrics
프로파일링 도구 활용으로 병목 지점을 정확히 식별합니다.
Arm Mobile Studio나 Intel VTune 같은 전문 도구를 사용하여 CPU, GPU, 메모리 사용 패턴을 상세히 분석할 수 있습니다.
A/B 테스트 프레임워크 구축으로 최적화 효과를 정량적으로 검증합니다.
서로 다른 최적화 기법을 적용한 모델들의 성능을 동일한 조건에서 비교 측정하여 최적의 설정을 찾아냅니다.
미래 기술 동향과 대응 전략
Edge AI 디바이스 최적화 분야는 급속히 진화하고 있습니다.
차세대 하드웨어 아키텍처에 대한 준비가 필요합니다.
ARM의 신규 Cortex-X 시리즈나 RISC-V 기반 AI 전용 프로세서들이 등장하고 있어,
이러한 새로운 플랫폼에 최적화된 개발 역량을 미리 준비해야 합니다.
연합 학습(Federated Learning) 기술과의 융합도 주목할 만합니다.
개별 엣지 디바이스에서 학습한 지식을 중앙 서버로 전송하여 글로벌 모델을 개선하면서도,
개인정보는 로컬에 보관하는 혁신적인 접근법입니다.
Google의 연구에 따르면, 이 기술로 데이터 전송량을 90% 이상 줄이면서도 모델 성능을 향상시킬 수 있습니다.
신경망 구조 탐색(Neural Architecture Search) 자동화도 중요한 트렌드입니다.
특정 하드웨어 제약 조건에 최적화된 신경망 구조를 자동으로 탐색하는 기술이 발전하여,
수동 최적화의 한계를 뛰어넘을 것으로 예상됩니다.
결론 및 실무 적용 가이드
스마트 디바이스 성능 튜닝은 이제 AI 개발자들에게 필수적인 역량이 되었습니다.
성공적인 Edge AI 디바이스 최적화를 위해서는 다음 핵심 원칙들을 지켜야 합니다:
단계적 최적화 접근법을 채택하세요.
모델 경량화부터 시작하여 하드웨어 가속, 메모리 최적화, 전력 관리 순으로 점진적으로 적용하면 각 단계의 효과를 명확히 측정할 수 있습니다.
실제 운영 환경에서의 검증을 반드시 수행하세요.
개발 환경에서의 벤치마크 결과와 실제 디바이스에서의 성능은 상당한 차이를 보일 수 있습니다.
지속적인 모니터링과 개선이 필요합니다.
엣지 디바이스는 다양한 환경 조건과 사용 패턴에 노출되므로, 실시간 성능 데이터를 바탕으로 지속적인 튜닝이 필요합니다.
앞으로도 엣지 컴퓨팅 기술은 더욱 정교해지고 복잡해질 것입니다.
하지만 본 글에서 제시한 기본 원칙과 실무 기법들을 체계적으로 습득한다면, 변화하는 기술 환경에도 유연하게 대응할 수 있을 것입니다.
AI의 미래는 클라우드가 아닌 우리 손안의 디바이스에서 펼쳐질 것입니다.
지금부터 Edge AI 디바이스 최적화 역량을 체계적으로 구축하여, 다가오는 AI 시대의 핵심 기술을 선점하시기 바랍니다.
'AI 트렌드 & 뉴스' 카테고리의 다른 글
| MCP AI 완벽 가이드 2025: Model Context Protocol로 AI와 데이터를 연결하는 혁신적 방법 (0) | 2025.07.01 |
|---|---|
| Gemini CLI vs Claude CLI vs OpenAI CLI – 2025년 AI 명령줄 툴 완벽 비교 & 실사용 후기 (0) | 2025.06.26 |
| 생성형 AI 파인튜닝 실무 시리즈: Fine-tuning GPT 실무 완벽 가이드 (0) | 2025.06.25 |
| AI 기반 코드 리뷰 자동화 실전: 도입부터 ROI까지 (0) | 2025.06.25 |
| GPT-4o vs GPT-4.1 코딩 성능 완벽 비교: 개발자를 위한 최적 모델 선택 가이드 (벤치마크 테스트, 실제 프로젝트 적용 사례, 비용 효율성 분석) (0) | 2025.06.25 |



