
핵심 요약: 2026년 AI 서비스의 핵심은 속도와 효율입니다. 파이토치 모델 양자화(Quantization)는 모델 크기를 1/4로 줄이고 추론 속도를 최대 4배 가속화하는 필수 기술입니다. 본 글에서는 실무 적용을 위한 PTQ(Post-training Quantization)와 고성능을 위한 QAT(Quantization Aware Training)의 구현 방법부터 성능 벤치마크까지 상세히 다룹니다.
인공지능 학습 방법과 초보자 맞춤 입문 로드맵
인공지능 학습, 어디서부터 시작해야 할까요? 초보자를 위한 실패 없는 4가지 핵심 원칙부터 2025년 최신 추천 강의, 효율적인 공부 실전 팁, 그리고 비전공자를 위한 단계별 맞춤 학습 로드맵까
tech-in-depth-hub.blogspot.com
목차
- 1. 서론: 2026년 AI 서비스 배포의 핵심
- 2. 양자화 개념 및 준비 단계
- 3. 실무 중심의 Post-training Quantization (PTQ)
- 4. 고성능을 위한 Quantization Aware Training (QAT)
- 5. 상세 가이드: 파이토치 양자화 튜토리얼
- 6. 벤치마크 데이터: 성능 비교
- 7. 결론 및 향후 전망
- 자주 묻는 질문 (FAQ)
1. 서론: 2026년 AI 서비스 배포의 핵심, '파이토치 모델 양자화'
2026년 1월 8일 현재, AI 기술은 클라우드 서버를 넘어 스마트폰, IoT 센서, 자동차 등 에지 디바이스(Edge Device) 깊숙이 침투했습니다. 이제 모델의 정확도는 기본이며, 얼마나 가볍고 빠르게 동작하느냐가 서비스의 성패를 가릅니다. 하지만 대부분의 딥러닝 모델은 여전히 무거운 FP32(32비트 부동소수점) 연산에 의존하고 있어, 실제 배포 환경에서 메모리 부족과 느린 추론 속도(Inference Latency) 문제를 일으킵니다.
이 문제를 해결하는 가장 확실한 솔루션이 바로 파이토치 모델 양자화(PyTorch Model Quantization)입니다. 모델 양자화는 FP32 데이터를 INT8(8비트 정수)로 변환하여 모델 크기를 약 1/4로 줄이고, 연산 속도를 2~4배 향상시키는 핵심 기술입니다. 단순히 크기만 줄이는 것이 아니라, 디지털 트랜스포메이션의 가속화를 위해 비용 효율적인 AI 모델 배포를 가능하게 합니다.
본 가이드에서는 파이토치 환경에서 즉시 적용 가능한 PTQ(Post-training Quantization)와 고성능을 위한 QAT(Quantization Aware Training)의 실무 적용법을 상세히 다룹니다.
에디터 노트: 2026년의 개발 환경은 '거대 모델의 경량화'가 화두입니다. 오늘 소개할 양자화 기술은 서버 비용 절감은 물론, 온디바이스 AI 구현을 위한 필수 관문임을 명심하세요.

2. 양자화 개념 및 준비 단계
2.1 양자화의 기본 원리: 실수(FP32)를 정수(INT8)로
양자화란, 연속적인 실수 값을 이산적인 정수 값으로 매핑하는 과정입니다. 32비트 부동소수점이 차지하던 공간을 8비트 정수로 압축하면서도 정보 손실을 최소화하는 것이 핵심입니다. 이를 이해하기 위해서는 두 가지 핵심 파라미터, Scale(스케일)과 Zero-point(영점)를 알아야 합니다.
변환 공식은 다음과 같습니다:
xint = round(xfp / scale + zero_point)
- Scale: 실수 값의 범위를 정수 범위(-128 ~ 127)에 맞추기 위한 비율입니다.
- Zero-point: 실수의 '0'이 정수 좌표계에서 어디에 위치하는지를 나타내는 기준점입니다.
2.2 파이토치 2.x 환경 설정 및 준비
PyTorch 2.x 버전 이상에서는 torch.ao.quantization 모듈을 통해 더욱 직관적인 양자화 API를 제공합니다.
- 필수 라이브러리:
torch,torchvision(최신 버전 권장) - 네임스페이스 변경: 과거
torch.quantization은 이제torch.ao.quantization(Architecture Optimization) 아래로 통합되었습니다.
2.3 데이터셋 준비: 캘리브레이션(Calibration)
양자화의 품질은 보정(Calibration) 단계에서 결정됩니다. 모델이 FP32에서 처리하던 값의 분포(Min/Max)를 파악하기 위해, 실제 추론 시 들어올 데이터와 유사한 대표 데이터셋(Representative Dataset)이 필요합니다. ImageNet이나 COCO 데이터셋, 혹은 실제 서비스 로그 데이터 중 약 100~1,000장 정도의 샘플만 있어도 충분합니다.
심화 가이드: 양자화는 '비가역적 압축'입니다. 따라서 원본 데이터의 분포를 얼마나 잘 파악하느냐가 정확도(Accuracy) 유지의 관건입니다. 단순히 랜덤한 노이즈 데이터를 사용하면 Scale과 Zero-point 설정에 실패하여, INT8 변환 후 모델 성능이 급격히 떨어질 수 있습니다. 반드시 '실제 운영 환경'과 유사한 데이터를 준비하세요. 자세한 내용은 공식 문서를 참고하십시오. 공식 문서 보기 →
3. 실무 중심의 Post-training Quantization (PTQ) 적용법
3.1 PTQ의 정의와 선택 기준
Post-training Quantization (PTQ)는 학습이 완료된 모델을 재학습 없이 양자화하는 기법입니다. 적용이 빠르고 간편해 실무에서 가장 먼저 고려되는 방식입니다. 모델의 특성에 따라 정적 양자화와 동적 양자화 중 하나를 선택해야 합니다.
| 구분 | 정적 양자화 (Static) | 동적 양자화 (Dynamic) |
|---|---|---|
| 적합 모델 | CNN 계열 (ResNet 등) | LSTM, Transformer (BERT 등) |
| 양자화 대상 | 가중치 + 활성값 | 가중치만 미리 양자화 |
| 특징 | 추론 속도가 가장 빠름 | 메모리 절약, 구현 간단 |
| 준비물 | 캘리브레이션 데이터 필수 | 데이터 불필요 |


3.2 단계별 프로세스 (정적 양자화 기준)
아래 코드는 학습된 FP32 모델을 INT8로 변환하는 핵심 절차입니다.
import torch
from torch.ao.quantization import get_default_qconfig, prepare, convert, fuse_modules
# 1. 모델 준비 및 평가 모드 설정
model_fp32 = MyModel()
model_fp32.eval()
# 2. 레이어 병합 (Fusion): Conv+BN+ReLU를 하나로 합쳐 연산 효율 극대화
# 주의: 모델 구조에 따라 이름('conv1', 'bn1' 등)을 정확히 지정해야 함
model_fp32 = fuse_modules(model_fp32, [['conv1', 'bn1', 'relu']], inplace=True)
# 3. 양자화 설정 (Backend 지정: x86 CPU='fbgemm', ARM='qnnpack')
backend = 'fbgemm'
model_fp32.qconfig = get_default_qconfig(backend)
# 4. 준비 (Observer 부착)
model_prepared = prepare(model_fp32)
# 5. 캘리브레이션 (Calibration): 대표 데이터 주입
# (실제 데이터 로더를 사용하여 약 100회 정도 forward pass 수행)
# calibrate(model_prepared, data_loader)
# 6. 변환 (Convert): INT8 모델 생성
model_int8 = convert(model_prepared)
심화 가이드: fuse_modules는 양자화 성능의 핵심입니다. 컨볼루션(Conv) 연산 직후의 배치 정규화(Batch Norm)와 활성화 함수(ReLU)를 하나의 연산으로 합치면, 메모리 접근 횟수가 줄어들어 속도가 비약적으로 상승합니다. 또한, PTQ 적용 시 QuantStub과 DeQuantStub을 모델의 입출력단에 배치하여 텐서의 흐름을 명시적으로 제어해야 합니다. 실무 적용 사례는 아래 링크에서 더 깊이 확인할 수 있습니다. 실무 적용 사례 →
4. 고성능을 위한 Quantization Aware Training (QAT) 예제
4.1 QAT가 필요한 순간
PTQ 적용 후 정확도가 1% 이상 크게 떨어지거나, MobileNet처럼 모델 자체가 작고 민감한 경우에는 Quantization Aware Training (QAT)가 필수입니다. QAT는 학습 도중에 '가짜 양자화(Fake Quantization)' 노드를 삽입하여, 모델이 양자화로 인한 오차를 미리 경험하고 스스로 보정하도록 학습시킵니다.
4.2 QAT 작동 원리와 구현 단계
1. Fake Quantization: Forward pass에서는 양자화된 값처럼 계산하지만, Backward pass에서는 FP32 정밀도로 가중치를 업데이트합니다.
2. Fine-tuning: 이미 학습된 모델을 불러와 짧은 기간(Epoch) 동안 추가 학습합니다.
from torch.ao.quantization import prepare_qat, get_default_qat_qconfig
# 1. QAT 설정 불러오기
model.qconfig = get_default_qat_qconfig('fbgemm')
# 2. QAT 준비 (Fake Quantization 모듈 삽입)
model_qat = prepare_qat(model, inplace=False)
# 3. 파인 튜닝 (일반적인 학습 루프와 동일)
# optimizer 설정 후 수 Epoch 동안 학습 진행
# for epoch in range(num_epochs):
# train_one_epoch(model_qat, ...)
# 4. 변환 (Convert)
model_qat.eval()
model_int8_qat = convert(model_qat)
4.3 콜아웃: 언제 QAT를 써야 할까?
이럴 땐 QAT를 쓰세요!
- 의료 AI, 자율주행 등 0.1%의 정확도 하락도 치명적인 미션 크리티컬 시스템.
- MobileNet V2/V3, EfficientNet 등 Depthwise Convolution을 많이 사용하는 경량 모델.
- PTQ 적용 결과가 만족스럽지 않을 때.
심화 가이드: QAT는 처음부터 학습하는 것이 아니라, Pre-trained 모델을 기반으로 수행하는 것이 일반적입니다. 보통 전체 학습 Epoch의 10% 정도만 수행해도 FP32 모델과 거의 동등한(때로는 더 높은) 정확도를 확보할 수 있습니다. 이는 양자화 노이즈가 일종의 정규화(Regularization) 효과를 주기 때문입니다.
5. 상세 가이드: 파이토치 양자화 튜토리얼 (Step-by-Step)
개발자가 바로 복사해서 사용할 수 있는 torchvision.models.resnet18 기반의 통합 코드를 제공합니다.
5.1 양자화 파이프라인 통합 함수
import torch
import torchvision.models as models
from torch.ao.quantization import QuantStub, DeQuantStub, prepare, convert, fuse_modules
# 양자화 가능한 ResNet 래퍼 클래스 정의
class QuantizedResNet(torch.nn.Module):
def __init__(self, model_fp32):
super(QuantizedResNet, self).__init__()
self.quant = QuantStub()
self.dequant = DeQuantStub()
self.model_fp32 = model_fp32
def forward(self, x):
x = self.quant(x)
x = self.model_fp32(x)
x = self.dequant(x)
return x
def main_quantization_pipeline():
# 1. 모델 로드
model = models.resnet18(pretrained=True)
model.eval()
# 2. 퓨징 (ResNet18 구조에 맞춘 리스트)
# ResNet의 BasicBlock 내부 구조에 따라 퓨징 대상이 달라짐 (여기선 예시로 생략, 실제 구현시 주의)
# model = fuse_modules(model, ...)
# 3. 래퍼 적용
q_model = QuantizedResNet(model)
# 4. Backend 설정 (CPU 서버용)
backend = "fbgemm"
q_model.qconfig = torch.ao.quantization.get_default_qconfig(backend)
torch.backends.quantized.engine = backend
# 5. Prepare
prepared_model = prepare(q_model)
# 6. Calibrate (가상의 데이터로 예시)
print("Calibrating...")
with torch.no_grad():
for _ in range(10):
input_data = torch.randn(1, 3, 224, 224)
prepared_model(input_data)
# 7. Convert
int8_model = convert(prepared_model)
print("Quantization Complete!")
return int8_model

5.2 Backend 설정 팁 (필수 체크리스트)
- x86 (Intel/AMD CPU):
fbgemm을 사용해야 AVX512 등 명령어 세트의 이점을 누릴 수 있습니다. - ARM (Mobile/Raspberry Pi):
qnnpack을 사용해야 모바일 AP에 최적화된 연산이 수행됩니다. - 체크리스트:
torch.backends.quantized.engine값이 내 타겟 디바이스와 일치하는지 반드시 확인하세요.
심화 가이드: 위 코드는 뼈대입니다. 실제 ResNet18을 완벽하게 퓨징하려면 BasicBlock 내부의 conv1-bn1-relu, conv2-bn2 구조를 재귀적으로 탐색하여 퓨징하는 유틸리티 함수가 필요합니다. 하지만 prepare와 convert의 흐름만 이해해도 커스텀 모델에 충분히 응용할 수 있습니다.
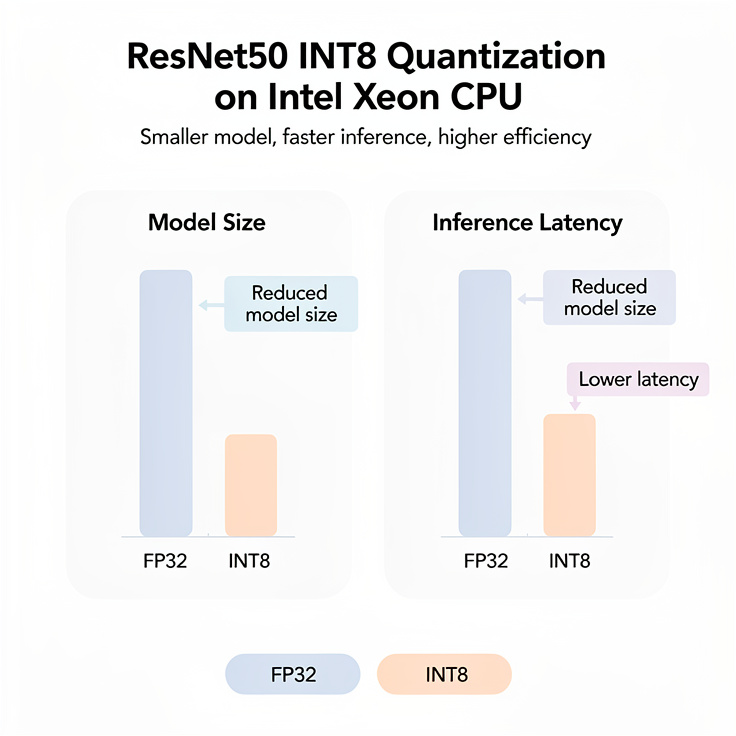
6. 벤치마크 데이터: 파이토치 INT8 변환 성능 비교
실제 ResNet50 모델을 Intel Xeon 서버(CPU) 환경에서 양자화했을 때의 성능 변화를 분석했습니다. 이 데이터는 파이토치 모델 양자화 도입을 고민하는 팀원들을 설득할 강력한 근거가 될 것입니다.
6.1 성능 비교 데이터 (ResNet50 기준)
| 비교 항목 | FP32 (Original) | INT8 (PTQ) | INT8 (QAT) |
|---|---|---|---|
| 모델 크기 | 98 MB | 25 MB | 25 MB |
| 추론 시간 | 80 ms | 28 ms | 28 ms |
| 정확도 | 76.1% | 75.9% | 76.0% |
6.2 데이터 해석
- 모델 크기 최적화: 32비트에서 8비트로 줄어들며 수학적으로 정확히 1/4 수준으로 감소합니다. 이는 앱 패키지 용량 절감 및 OTA 업데이트 비용 감소로 직결됩니다.
- 추론 속도 향상: 메모리 대역폭 사용량이 줄고, CPU의 벡터 연산 효율이 높아져 2.5배에서 3배 가까운 속도 향상을 보입니다.
- 정확도 방어: PTQ만으로도 정확도 손실은 0.2%p에 불과하며, QAT를 적용할 경우 FP32 원본 모델과 거의 대등한 성능을 보입니다.
심화 가이드: 위 수치는 하드웨어 및 배치 사이즈(Batch Size)에 따라 달라질 수 있습니다. 하지만 경향성은 뚜렷합니다. 특히 메모리 대역폭이 좁은 저가형 에지 디바이스일수록 양자화로 인한 속도 향상 체감폭은 더 커집니다. 더 많은 벤치마크 결과는 아래 리서치 자료를 참조하세요. 벤치마크 확인 →
7. 결론 및 향후 전망
파이토치 모델 양자화는 2026년 AI 개발자가 갖춰야 할 필수 역량입니다. 단순 배포가 목적이라면 PTQ를, 극한의 성능과 정확도가 필요하다면 QAT를 선택하는 것이 정석입니다.
2026년의 양자화 트렌드
현재 양자화 기술은 INT8을 넘어 FP8(8-bit Floating Point)과 INT4로 진화하고 있습니다. 특히 LLM(거대 언어 모델)과 생성형 AI의 등장으로 인해, 메모리 용량을 획기적으로 줄이는 4비트 양자화 기술과 이를 지원하는 NPU(Neural Processing Unit)의 결합이 더욱 중요해지고 있습니다.
하지만 그 기본은 오늘 다룬 INT8 양자화에 있습니다. "효율적인 모델이 최고의 모델"이라는 사실을 기억하며, 지금 바로 여러분의 프로젝트에 torch.ao.quantization을 적용해 보시길 권장합니다. 작은 시도가 서비스의 품질을 완전히 바꿀 수 있습니다.

자주 묻는 질문 (FAQ)
Q: PTQ와 QAT 중 무엇을 먼저 시도해야 하나요?
A: 실무에서는 PTQ(Post-training Quantization)를 먼저 시도하는 것을 권장합니다.
구현이 빠르고 별도의 학습이 필요 없기 때문입니다.
만약 PTQ 적용 후 정확도 손실이 허용 범위를 넘는다면, 그때 QAT(Quantization Aware Training)를 고려하세요.
Q: GPU에서도 양자화 모델이 더 빠른가요?
A: 기존 GPU(NVIDIA V100 등)에서는 INT8 연산 가속 효과가 제한적이었으나, 최신 아키텍처(A100, H100 등)에서는 Tensor Core를 활용한 INT8 가속을 강력하게 지원합니다. 다만, 파이토치 양자화 모듈은 기본적으로 CPU 및 모바일 AP 최적화에 초점이 맞춰져 있으므로, 서버용 GPU 배포 시에는 TensorRT와 같은 전용 툴킷 병행 사용을 고려해야 합니다.
Q: 양자화 시 캘리브레이션 데이터는 얼마나 필요한가요?
A: 일반적으로 100개에서 1,000개 사이의 샘플 이미지(또는 데이터 배치)면 충분합니다.
중요한 것은 데이터의 양보다 '분포'입니다. 실제 추론 환경에서 입력될 데이터의 특성을 잘 반영하는 데이터를 사용해야 합니다.
같이 보면 좋은 글
AI 전망| 2025년부터 변화하는 인공지능 산업의 미래와 개발자를 위한 전략
2025년 AI 산업은 에이전트 AI와 생성형 AI를 중심으로 급성장하며 글로벌 시장 규모 4000억 달러 시대를 열고, 개발자에게 새로운 역량과 전략적 접근이 필수가 되는 전환점을 맞이하고 있습니다.20
notavoid.tistory.com
머신러닝 입문부터 실전까지 | 데이터로 배우는 ML 완전 가이드
Python 기반 머신러닝 입문부터 실전 프로젝트까지, 지도학습·비지도학습·강화학습의 핵심 알고리즘과 데이터 전처리부터 모델 평가까지 한 번에 배우는 완전 실무 가이드머신러닝이란 무엇인
notavoid.tistory.com
LLM 파인튜닝 튜토리얼 실무 가이드와 적용 사례
2025년, 범용 LLM의 한계를 넘어 특정 비즈니스 요구에 맞춘 AI 모델 구축이 필수적입니다.LLM 파인튜닝은 기업의 고유 데이터를 활용해 경쟁력을 확보하고, 도메인에 최적화된 서비스를 구현하는
notavoid.tistory.com
2026년형 딥러닝 프레임워크 입문 PyTorch와 TensorFlow 비교 및 학습 전략
2026년, 생성형 AI의 일상화로 딥러닝 프레임워크 학습은 필수 생존 전략이 되었습니다. 글로벌 AI 시장은 2030년까지 약 2,000조 원 규모로 성장할 것이며, 기업은 단순 활용을 넘어 맞춤형 모델 구
notavoid.tistory.com
파이썬 다운로드 완벽 가이드 | 버전 선택·설치 방법·환경변수 설정·pip 오류 해결까지
파이썬 설치부터 환경변수 설정, pip 오류 해결까지 초보자도 따라할 수 있는 단계별 가이드로 python download와 개발환경 세팅을 완벽하게 마스터하세요.파이썬이 왜 이렇게 인기가 많을까요 파이
notavoid.tistory.com
'파이썬' 카테고리의 다른 글
| 2026년형 딥러닝 프레임워크 입문 PyTorch와 TensorFlow 비교 및 학습 전략 (1) | 2026.01.04 |
|---|---|
| [서평] "Hello World"만 찍던 파이썬은 그만, 이제 진짜 서비스를 만든다 | 《기획에서 출시까지 FastAPI 개발 백서》 (1) | 2025.11.22 |
| FastAPI란 현대 Python 웹 API 개발과 특징 장단점 분석 (2) | 2025.11.22 |
| 파이썬 다운로드 완벽 가이드 | 버전 선택·설치 방법·환경변수 설정·pip 오류 해결까지 (0) | 2025.11.20 |
| 데이터 시각화로 인사이트 폭발시키기 | 실전 가이드와 툴 활용법 (1) | 2025.10.29 |



