
PyTorch는 동적 계산 그래프와 직관적인 Python API로 연구부터 프로덕션까지 전 과정을 지원하는 딥러닝 프레임워크로,
텐서 연산부터 GPU 가속, 자동미분, 신경망 구축, 모델 배포까지 실전 프로젝트에 필요한 모든 기능을 제공합니다.
PyTorch가 2025년 딥러닝의 표준이 된 이유

딥러닝을 시작하려는 개발자라면 한 번쯤 고민하게 됩니다.
"어떤 프레임워크로 시작해야 할까?"
2025년 현재, PyTorch는 AI 연구 논문의 70% 이상에서 사용되며 Meta, OpenAI, Tesla와 같은 글로벌 기업들의 프로덕션 환경에서 실제로 운영되고 있습니다.
PyTorch 공식 홈페이지에서는 다양한 튜토리얼과 함께 최신 버전의 설치 가이드를 제공하고 있습니다.
PyTorch
PyTorch Foundation is the deep learning community home for the open source PyTorch framework and ecosystem.
pytorch.org
PyTorch의 핵심 철학과 장점

Python 중심 설계로 누구나 쉽게 시작
PyTorch의 가장 큰 강점은 Python 생태계와의 완벽한 통합입니다.
NumPy와 유사한 문법 구조를 가지고 있어 Python 개발자라면 별도의 학습 곡선 없이 바로 시작할 수 있습니다.
일반적인 Python 코드를 작성하듯 딥러닝 모델을 구현할 수 있어 직관적이고 디버깅이 용이합니다.
동적 계산 그래프의 혁신
PyTorch는 동적 계산 그래프(Dynamic Computation Graph)를 채택하여 코드 실행 중에도 모델 구조를 변경할 수 있습니다.
이는 연구자들이 새로운 아이디어를 빠르게 프로토타이핑하고 실험하는 데 매우 유용합니다.
일반적인 Python 디버거를 사용하여 모델의 각 단계를 추적하고 문제를 해결할 수 있어 개발 생산성이 크게 향상됩니다.
강력한 커뮤니티와 생태계
PyTorch는 활발한 오픈소스 커뮤니티와 함께 성장하고 있습니다.
PyTorch 공식 튜토리얼에서는 초보자부터 전문가까지 모든 수준의 학습 자료를 제공합니다.
Welcome to PyTorch Tutorials — PyTorch Tutorials 2.9.0+cu128 documentation
Jacobians, Hessians, hvp, vhp, and more Learn how to compute advanced autodiff quantities using torch.func Frontend-APIs
docs.pytorch.org
TorchVision(컴퓨터 비전), TorchAudio(음성 처리), Hugging Face Transformers(자연어 처리) 등 풍부한 라이브러리 생태계가 구축되어 있습니다.
PyTorch 시작하기
개발 환경 구성
PyTorch 설치는 매우 간단합니다.
시스템 환경과 CUDA 버전에 맞는 패키지를 선택하여 설치할 수 있습니다.
# CPU 버전 설치
pip install torch torchvision torchaudio
# GPU 버전 설치 (CUDA 12.1)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
가상 환경을 사용하면 프로젝트별로 독립적인 개발 환경을 유지할 수 있어 권장됩니다.
Conda를 사용하는 경우에도 동일한 방식으로 설치 가능합니다.
첫 번째 PyTorch 코드 작성
간단한 텐서 연산부터 시작해봅시다.
import torch
# 텐서 생성
x = torch.tensor([[1, 2], [3, 4]], dtype=torch.float32)
y = torch.tensor([[5, 6], [7, 8]], dtype=torch.float32)
# 텐서 연산
z = x + y
print(f"덧셈 결과: {z}")
# GPU 사용 가능 여부 확인
if torch.cuda.is_available():
x_gpu = x.to('cuda')
print(f"GPU에서 실행: {x_gpu.device}")이 코드는 PyTorch의 기본적인 텐서 생성과 연산을 보여줍니다.
GPU가 사용 가능한 경우 자동으로 GPU에서 연산을 수행하여 성능을 크게 향상시킬 수 있습니다.
텐서 연산의 기초
PyTorch 텐서의 이해
텐서는 PyTorch의 핵심 데이터 구조입니다.
NumPy 배열과 유사하지만 GPU에서 실행할 수 있다는 점이 큰 차이입니다.
스칼라(0차원), 벡터(1차원), 행렬(2차원)부터 다차원 텐서까지 모든 형태의 데이터를 표현할 수 있습니다.
import torch
# 다양한 텐서 생성 방법
zeros = torch.zeros(3, 4) # 0으로 채워진 텐서
ones = torch.ones(2, 3) # 1로 채워진 텐서
random = torch.randn(2, 3) # 정규분포 난수
arange = torch.arange(0, 10, 2) # 범위 지정
# 텐서 형태 변경
x = torch.randn(2, 3, 4)
reshaped = x.view(2, 12) # 형태 변경
flattened = x.flatten() # 1차원으로 평탄화GPU 가속 활용하기
PyTorch의 강력한 기능 중 하나는 GPU 가속입니다.
CUDA를 지원하는 NVIDIA GPU가 있다면 간단한 코드 변경만으로 수백 배의 성능 향상을 얻을 수 있습니다.
# GPU 디바이스 설정
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 텐서를 GPU로 이동
x = torch.randn(1000, 1000).to(device)
y = torch.randn(1000, 1000).to(device)
# GPU에서 행렬 곱셈 수행
result = torch.matmul(x, y)대규모 모델을 학습할 때는 GPU 메모리 관리가 중요합니다.
불필요한 텐서는 적절히 삭제하고, 배치 크기를 조정하여 메모리 사용을 최적화해야 합니다.
자동미분(Autograd)으로 그래디언트 계산

Autograd의 작동 원리
PyTorch의 자동미분 시스템은 딥러닝의 핵심인 역전파를 자동으로 처리합니다.
모든 연산을 추적하여 계산 그래프를 동적으로 구성하고, 이를 통해 그래디언트를 자동으로 계산합니다.
import torch
# requires_grad=True로 그래디언트 추적 활성화
x = torch.tensor([2.0], requires_grad=True)
y = torch.tensor([3.0], requires_grad=True)
# 연산 수행
z = x**2 + y**3
# 역전파로 그래디언트 계산
z.backward()
print(f"dz/dx = {x.grad}") # 2x = 4
print(f"dz/dy = {y.grad}") # 3y² = 27실전에서의 Autograd 활용
신경망 학습 시 손실 함수의 그래디언트를 계산하는 과정이 자동화됩니다.
개발자는 순전파 과정만 정의하면 역전파는 PyTorch가 자동으로 처리합니다.
import torch.nn as nn
import torch.optim as optim
# 간단한 선형 회귀 모델
model = nn.Linear(1, 1)
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 학습 루프
for epoch in range(100):
# 순전파
predictions = model(x_train)
loss = criterion(predictions, y_train)
# 그래디언트 초기화 및 역전파
optimizer.zero_grad()
loss.backward()
optimizer.step()PyTorch Autograd 공식 문서에서 더 자세한 내용을 확인할 수 있습니다.
신경망 구축의 기초
torch.nn 모듈 활용
PyTorch는 torch.nn 모듈을 통해 신경망 구축을 위한 다양한 계층과 함수를 제공합니다.
모든 신경망 모델은 nn.Module 클래스를 상속받아 구현됩니다.
import torch
import torch.nn as nn
class SimpleNeuralNetwork(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleNeuralNetwork, self).__init__()
# 계층 정의
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
# 순전파 정의
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# 모델 인스턴스 생성
model = SimpleNeuralNetwork(input_size=784, hidden_size=128, output_size=10)데이터 로더와 전처리
효율적인 학습을 위해서는 데이터를 적절히 로드하고 전처리해야 합니다.
PyTorch는 DataLoader와 Dataset 클래스를 제공하여 배치 처리와 데이터 셔플링을 간편하게 수행할 수 있습니다.
from torch.utils.data import DataLoader, TensorDataset
from torchvision import datasets, transforms
# 데이터 변환 정의
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# MNIST 데이터셋 로드
train_dataset = datasets.MNIST(
root='./data',
train=True,
download=True,
transform=transform
)
# 데이터 로더 생성
train_loader = DataLoader(
train_dataset,
batch_size=64,
shuffle=True,
num_workers=2
)배치 크기는 GPU 메모리와 학습 속도를 고려하여 적절히 선택해야 합니다.
일반적으로 32, 64, 128과 같은 2의 거듭제곱 값을 사용합니다.
CNN 모델 구현하기
컨볼루션 신경망의 기초
CNN 모델은 이미지 처리에 특화된 신경망 구조입니다.
컨볼루션 계층, 풀링 계층, 완전 연결 계층을 조합하여 강력한 이미지 분류 모델을 만들 수 있습니다.
import torch.nn as nn
import torch.nn.functional as F
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 컨볼루션 계층
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
# 풀링 계층
self.pool = nn.MaxPool2d(2, 2)
# 완전 연결 계층
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
# 드롭아웃
self.dropout = nn.Dropout(0.5)
def forward(self, x):
# 첫 번째 컨볼루션 블록
x = self.pool(F.relu(self.conv1(x)))
# 두 번째 컨볼루션 블록
x = self.pool(F.relu(self.conv2(x)))
# 평탄화
x = x.view(-1, 64 * 7 * 7)
# 완전 연결 계층
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x이미지 분류 실전 프로젝트
실제 프로젝트에서는 사전 학습된 모델을 활용하는 것이 효율적입니다.
TorchVision은 ResNet, VGG, EfficientNet 등 다양한 사전 학습 모델을 제공합니다.
import torchvision.models as models
# 사전 학습된 ResNet 모델 로드
model = models.resnet50(pretrained=True)
# 마지막 계층만 새로운 태스크에 맞게 변경
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, 10) # 10개 클래스 분류
# 특정 계층만 학습하도록 설정
for param in model.parameters():
param.requires_grad = False
# 마지막 계층만 학습 가능하도록 설정
for param in model.fc.parameters():
param.requires_grad = True전이 학습(Transfer Learning)을 활용하면 적은 데이터로도 높은 정확도를 달성할 수 있습니다.
RNN과 Transformer 모델
순환 신경망(RNN) 구현
RNN은 시퀀스 데이터를 처리하는 데 특화된 신경망입니다.
텍스트, 시계열 데이터, 음성 등 순차적 패턴을 학습할 수 있습니다.
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# LSTM 계층
self.lstm = nn.LSTM(
input_size,
hidden_size,
num_layers,
batch_first=True,
dropout=0.2
)
# 출력 계층
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
# 초기 은닉 상태 및 셀 상태
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
# LSTM 순전파
out, _ = self.lstm(x, (h0, c0))
# 마지막 타임스텝의 출력만 사용
out = self.fc(out[:, -1, :])
return outTransformer 아키텍처
Transformer는 현대 자연어 처리의 표준 아키텍처입니다.
어텐션 메커니즘을 통해 장거리 의존성을 효과적으로 학습할 수 있습니다.
# Transformer 인코더 레이어 사용
encoder_layer = nn.TransformerEncoderLayer(
d_model=512,
nhead=8,
dim_feedforward=2048,
dropout=0.1
)
# Transformer 인코더
transformer_encoder = nn.TransformerEncoder(
encoder_layer,
num_layers=6
)
# 입력 데이터 처리
src = torch.randn(10, 32, 512) # (sequence_length, batch_size, d_model)
output = transformer_encoder(src)Hugging Face Transformers는 BERT, GPT 등 최신 Transformer 모델을 손쉽게 사용할 수 있게 해줍니다.
모델 학습 최적화
옵티마이저 선택
적절한 옵티마이저 선택은 모델 성능에 큰 영향을 미칩니다.
Adam, SGD, AdamW 등 다양한 옵티마이저가 제공됩니다.
import torch.optim as optim
# Adam 옵티마이저
optimizer = optim.Adam(model.parameters(), lr=0.001)
# SGD with momentum
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# AdamW (weight decay 포함)
optimizer = optim.AdamW(model.parameters(), lr=0.001, weight_decay=0.01)학습률 스케줄링
학습률 스케줄러를 사용하면 학습 과정에서 학습률을 동적으로 조정할 수 있습니다.
이는 모델이 더 나은 최적점을 찾도록 도와줍니다.
from torch.optim.lr_scheduler import StepLR, CosineAnnealingLR
# Step 스케줄러 - 일정 주기마다 학습률 감소
scheduler = StepLR(optimizer, step_size=10, gamma=0.1)
# Cosine Annealing 스케줄러
scheduler = CosineAnnealingLR(optimizer, T_max=100)
# 학습 루프에서 사용
for epoch in range(num_epochs):
train_one_epoch(model, train_loader, optimizer)
scheduler.step() # 학습률 업데이트
정규화 기법
과적합을 방지하기 위한 다양한 정규화 기법을 적용할 수 있습니다.
드롭아웃, 배치 정규화, L2 정규화 등이 있습니다.
# 드롭아웃
dropout = nn.Dropout(p=0.5)
# 배치 정규화
batch_norm = nn.BatchNorm1d(num_features=128)
# L2 정규화 (weight decay)
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-5)PyTorch 실전 프로젝트 예제
이미지 분류 프로젝트 전체 코드
실제 프로젝트에서는 데이터 준비, 모델 정의, 학습, 평가의 전 과정이 필요합니다.
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# 디바이스 설정
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 데이터 전처리
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 데이터 로드
train_dataset = datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64,
shuffle=True, num_workers=4)
# 모델 정의 및 설정
model = models.resnet18(pretrained=True)
model.fc = nn.Linear(model.fc.in_features, 10)
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 학습 함수
def train_epoch(model, loader, criterion, optimizer, device):
model.train()
running_loss = 0.0
correct = 0
total = 0
for inputs, labels in loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
return running_loss / len(loader), 100. * correct / total
# 학습 실행
for epoch in range(10):
train_loss, train_acc = train_epoch(model, train_loader,
criterion, optimizer, device)
print(f'Epoch {epoch+1}: Loss={train_loss:.4f}, Acc={train_acc:.2f}%')모델 저장과 불러오기
학습된 모델을 저장하고 나중에 재사용할 수 있습니다.
# 모델 전체 저장
torch.save(model.state_dict(), 'model_checkpoint.pth')
# 모델 불러오기
model = SimpleNeuralNetwork(input_size, hidden_size, output_size)
model.load_state_dict(torch.load('model_checkpoint.pth'))
model.eval() # 평가 모드로 전환
# 옵티마이저 상태도 함께 저장
checkpoint = {
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
}
torch.save(checkpoint, 'checkpoint.pth')모델 배포 전략
TorchScript를 활용한 모델 최적화
프로덕션 환경에서는 모델을 최적화하여 추론 속도를 높이는 것이 중요합니다.
TorchScript는 PyTorch 모델을 직렬화하고 최적화하는 방법을 제공합니다.
import torch
# 모델을 평가 모드로 전환
model.eval()
# TorchScript로 변환 (tracing 방법)
example_input = torch.randn(1, 3, 224, 224)
traced_model = torch.jit.trace(model, example_input)
# 저장
traced_model.save('model_traced.pt')
# 불러오기
loaded_model = torch.jit.load('model_traced.pt')
loaded_model.eval()TorchServe를 이용한 프로덕션 배포
TorchServe는 PyTorch 모델을 REST API로 서빙하기 위한 공식 도구입니다.
멀티 모델 서빙, 모델 버전 관리, 모니터링 기능을 제공합니다.
# TorchServe 설치
pip install torchserve torch-model-archiver torch-workflow-archiver
# 모델 아카이브 생성
torch-model-archiver --model-name my_model \
--version 1.0 \
--serialized-file model.pth \
--handler image_classifier \
--export-path model_store
# TorchServe 실행
torchserve --start --ncs \
--model-store model_store \
--models my_model=my_model.marTorchServe 공식 문서에서 자세한 배포 가이드를 확인할 수 있습니다.
TorchServe — PyTorch/Serve master documentation
Shortcuts
docs.pytorch.org
Docker 컨테이너화
모델을 Docker 컨테이너로 패키징하면 어떤 환경에서도 일관되게 실행할 수 있습니다.
FROM pytorch/pytorch:latest
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY model.pth .
COPY app.py .
CMD ["python", "app.py"]클라우드 배포 옵션
AWS SageMaker, Google Cloud Vertex AI, Azure ML 등 다양한 클라우드 플랫폼에서 PyTorch 모델을 배포할 수 있습니다.
각 플랫폼은 스케일링, 모니터링, A/B 테스팅 등의 기능을 제공합니다.
PyTorch vs TensorFlow 비교
주요 차이점 분석
2025년 현재, PyTorch와 TensorFlow는 각각의 강점을 가지고 있습니다.
| 비교 항목 | PyTorch | TensorFlow |
|---|---|---|
| 학습 곡선 | Python 친화적이고 직관적 | Keras API로 개선되었으나 여전히 복잡 |
| 계산 그래프 | 동적 그래프 (Define-by-Run) | 정적/동적 하이브리드 |
| 디버깅 | Python 디버거 직접 사용 가능 | 디버깅이 상대적으로 어려움 |
| 연구 분야 | AI 연구의 70% 이상 사용 | 엔터프라이즈 환경에서 강세 |
| 프로덕션 배포 | TorchServe, TorchScript | TF Serving, TFLite (모바일 강점) |
| 커뮤니티 | 학계 중심, 빠르게 성장 | 기업 중심, 오래된 생태계 |
| 하드웨어 지원 | CUDA, ROCm, MPS | CUDA, TPU 최적화 |
| 성능 | torch.compile()로 대폭 향상 | XLA로 최적화 가능 |
어떤 프레임워크를 선택해야 할까
PyTorch를 선택하는 경우
- 연구 및 프로토타이핑이 주요 목적인 경우
- Python 기반 개발에 익숙한 경우
- 최신 AI 논문을 재현하고 싶은 경우
- 디버깅과 실험이 빈번한 프로젝트
TensorFlow를 선택하는 경우
- 대규모 엔터프라이즈 환경에서의 배포
- 모바일 및 엣지 디바이스 배포가 필요한 경우
- TPU를 활용한 대규모 학습
- 안정적이고 검증된 프로덕션 파이프라인이 필요한 경우
실제로 많은 기업들이 연구 단계에서는 PyTorch를 사용하고,
프로덕션 배포 시에는 필요에 따라 TensorFlow로 전환하거나 ONNX를 통해 모델을 변환하는 전략을 사용합니다.
성능 최적화 팁
혼합 정밀도 학습
혼합 정밀도 학습(Mixed Precision Training)을 사용하면 학습 속도를 2배 이상 향상시킬 수 있습니다.
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
for epoch in range(num_epochs):
for inputs, labels in train_loader:
optimizer.zero_grad()
# 자동 혼합 정밀도
with autocast():
outputs = model(inputs)
loss = criterion(outputs, labels)
# 스케일링된 역전파
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()데이터 로딩 최적화
데이터 로딩이 병목이 되지 않도록 최적화해야 합니다.
train_loader = DataLoader(
train_dataset,
batch_size=64,
shuffle=True,
num_workers=4, # 멀티프로세싱
pin_memory=True, # GPU 전송 속도 향상
persistent_workers=True # 워커 재사용
)모델 가지치기와 양자화
모델 크기를 줄이고 추론 속도를 높이는 기법입니다.
import torch.quantization as quantization
# 동적 양자화
quantized_model = torch.quantization.quantize_dynamic(
model, {nn.Linear}, dtype=torch.qint8
)
# 모델 크기 비교
print(f"원본 모델 크기: {get_model_size(model)} MB")
print(f"양자화 모델 크기: {get_model_size(quantized_model)} MB")PyTorch Lightning으로 코드 단순화
PyTorch Lightning은 PyTorch 코드를 구조화하고 보일러플레이트를 줄여줍니다.
연구와 프로덕션 간의 간극을 줄이고, 재현성을 높이는 데 도움을 줍니다.
import pytorch_lightning as pl
class LitModel(pl.LightningModule):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(784, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
def forward(self, x):
return self.model(x)
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
self.log('train_loss', loss)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=0.001)
# 학습 실행
trainer = pl.Trainer(max_epochs=10, accelerator='gpu')
trainer.fit(model, train_loader)PyTorch Lightning 공식 문서에서 더 많은 기능을 확인할 수 있습니다.
실전 프로젝트 체크리스트
프로젝트 시작 전 준비사항
데이터 수집 및 전처리
- 충분한 양의 데이터 확보
- 데이터 정제 및 라벨링
- 학습/검증/테스트 세트 분리
개발 환경 설정
- Python 가상환경 구성
- PyTorch 및 필요 라이브러리 설치
- GPU 드라이버 및 CUDA 설정
모델 선택 및 설계
- 문제에 적합한 아키텍처 선택
- 베이스라인 모델 구현
- 하이퍼파라미터 초기값 설정
학습 파이프라인 구축
- 데이터 로더 구현
- 학습 루프 작성
- 로깅 및 체크포인트 설정
평가 및 최적화
- 성능 지표 모니터링
- 하이퍼파라미터 튜닝
- 모델 앙상블 고려
배포 준비
- 모델 최적화 (TorchScript, 양자화)
- API 서버 구현
- Docker 컨테이너화
자주 발생하는 문제 해결
GPU 메모리 부족 오류
- 배치 크기 줄이기
- 그래디언트 누적 사용
- 혼합 정밀도 학습 적용
과적합 문제
- 데이터 증강 적용
- 드롭아웃 및 정규화 추가
- 학습 데이터 양 늘리기
학습이 수렴하지 않음
- 학습률 조정
- 배치 정규화 적용
- 그래디언트 클리핑 사용
마치며
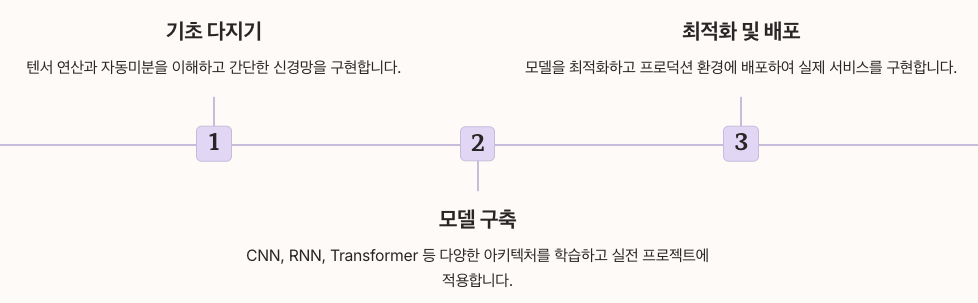
PyTorch는 딥러닝 입문자부터 전문 연구자까지 모두가 사용할 수 있는 강력하고 유연한 프레임워크입니다.
동적 계산 그래프, 직관적인 API, 풍부한 생태계를 통해 아이디어를 빠르게 구현하고 실험할 수 있습니다.
이 가이드에서 다룬 내용을 바탕으로 실제 프로젝트에 PyTorch를 적용해보세요.
텐서 연산부터 시작하여 자동미분, 신경망 구축, CNN 모델, RNN/Transformer, 그리고 최종적으로 모델 배포까지의 전 과정을 익히면 실전에서 바로 활용할 수 있는 딥러닝 역량을 갖추게 될 것입니다.
PyTorch 커뮤니티는 활발하게 성장하고 있으며, 새로운 기능과 최적화가 지속적으로 추가되고 있습니다.
PyTorch 공식 포럼과 GitHub 저장소를 통해 최신 정보를 확인하고 커뮤니티에 참여해보시기 바랍니다.
지금 바로 PyTorch로 첫 번째 딥러닝 프로젝트를 시작해보세요!
참고 자료
같이 보면 좋은 글
비주얼스튜디오코드 파이썬 | VS Code에서 Python 개발환경을 완벽하게 구축하는 방법
VS Code에서 Python 개발환경을 구축하는 방법을 Python interpreter 설정부터 가상환경 구성, 디버깅, 린팅까지 실무에 바로 적용 가능한 단계별 가이드로 제공합니다.왜 VS Code가 Python 개발에 최적인가 V
notavoid.tistory.com
Yappi란? 파이썬 코드 성능 분석을 위한 Yappi 프로파일러 사용법과 예제
Yappi는 파이썬 멀티스레드 애플리케이션의 성능 분석과 프로파일링을 위한 강력한 도구로, 기존 cProfile의 한계를 극복하고 실시간 성능 최적화를 가능하게 합니다.파이썬 개발자라면 누구나 한
notavoid.tistory.com
Pandas란? 데이터 분석을 위한 파이썬 라이브러리 완벽 가이드
Pandas Python 라이브러리 설치부터 데이터프레임, 시리즈 활용법까지 데이터 분석 완벽 가이드 - 실무 예제와 함께 배우는 판다스 사용법Pandas 소개와 기본 개념 Pandas는 파이썬에서 가장 널리 사용
notavoid.tistory.com
Python asyncio로 동시성 프로그래밍 마스터하기
현대 웹 개발과 데이터 처리에서 성능 최적화는 필수불가결한 요소입니다.특히 파이썬 asyncio 비동기 프로그래밍은 I/O 집약적인 작업을 효율적으로 처리하는 핵심 기술로 자리잡았습니다.이 글
notavoid.tistory.com
FastAPI로 고성능 REST API 만들기 - Flask 대안 탐색
FastAPI는 파이썬 웹 프레임워크 생태계에서 혁신적인 변화를 가져온 모던 프레임워크입니다.Flask보다 더 빠르고 직관적인 개발 경험을 제공하는 FastAPI는 REST API 개발에 최적화된 특징들을 갖추고
notavoid.tistory.com
'파이썬' 카테고리의 다른 글
| 파이썬 다운로드 완벽 가이드 | 버전 선택·설치 방법·환경변수 설정·pip 오류 해결까지 (0) | 2025.11.20 |
|---|---|
| 데이터 시각화로 인사이트 폭발시키기 | 실전 가이드와 툴 활용법 (1) | 2025.10.29 |
| 비주얼스튜디오코드 파이썬 | VS Code에서 Python 개발환경을 완벽하게 구축하는 방법 (1) | 2025.10.20 |
| Pandas란? 데이터 분석을 위한 파이썬 라이브러리 완벽 가이드 (0) | 2025.08.11 |
| Yappi란? 파이썬 코드 성능 분석을 위한 Yappi 프로파일러 사용법과 예제 (0) | 2025.07.16 |



