
Google TPU는 AI 워크로드를 위해 특별히 설계된 머신러닝 전용 가속기로, GPU 대비 최대 4.7배 높은 성능과 67% 향상된 에너지 효율을 제공하여 대형 언어모델 학습과 추론을 혁신적으로 가속화합니다.
Google TPU의 탄생과 진화

2016년 5월, Google은 Google I/O 컨퍼런스에서 처음으로 Tensor Processing Unit을 공개했습니다.
An in-depth look at Google’s first Tensor Processing Unit (TPU) | Google Cloud Blog
The TPU Matrix Multiplication Unit has a systolic array mechanism that contains 256 × 256 = total 65,536 ALUs. That means a TPU can process 65,536 multiply-and-adds for 8-bit integers every cycle. Because a TPU runs at 700MHz, a TPU can compute 65,536 ×
cloud.google.com
당시 AlphaGo가 이세돌 9단과의 역사적인 대국에서 이미 TPU를 활용하고 있었다는 사실은 많은 이들을 놀라게 했죠.
Google은 내부적으로 이미 2015년부터 TPU를 데이터센터에 배치해 사용하고 있었습니다.
Google 검색, Google 번역, Google 포토와 같은 서비스들이 모두 TPU의 힘으로 구동되고 있었던 것입니다.
TPU란 정확히 무엇인가

TPU는 Tensor Processing Unit의 약자로, AI 가속기의 한 종류인 ASIC(Application-Specific Integrated Circuit)입니다.
범용 프로세서인 CPU나 그래픽 처리에 특화된 GPU와 달리, TPU는 오직 머신러닝 하드웨어를 위해 처음부터 설계되었습니다.
특히 신경망에서 사용되는 행렬 연산 가속에 최적화되어 있는 것이 가장 큰 특징이죠.
딥러닝 칩으로서 TPU는 TensorFlow와의 긴밀한 통합을 통해 ML 워크로드를 효율적으로 처리합니다.
2024년 11월에는 7세대 TPU인 Ironwood가 공식 출시되면서 AI 추론 성능이 이전 세대 대비 4배 향상되었습니다.
3 things to know about Ironwood, our latest TPU
Google’s seventh-gen Tensor Processing Unit is here! Learn what makes Ironwood our most powerful and energy-efficient custom silicon to date.
blog.google
TPU의 핵심 아키텍처: Systolic Array
TPU가 다른 프로세서와 근본적으로 다른 점은 바로 Systolic Array 구조를 채택했다는 것입니다.
Systolic Array는 수천 개의 곱셈-누산 유닛(MAC: Multiply-Accumulate)을 직접 연결하여 거대한 물리적 행렬을 구성하는 방식입니다.
이 구조의 이름은 데이터가 마치 심장이 혈액을 펌핑하듯 칩을 통과하며 흐른다는 데서 유래했습니다.
Systolic Array의 동작 원리

TPU v3의 경우 단일 프로세서에 128 x 128 ALU로 구성된 두 개의 Systolic Array를 포함합니다.
초기 TPU v1은 256 x 256 구조로 총 65,536개의 8비트 MAC 유닛을 탑재하여 초당 92테라옵스의 처리 성능을 자랑했습니다.
행렬 곱셈을 수행할 때 TPU는 HBM 메모리에서 파라미터를 Matrix Multiplication Unit(MXU)로 로드합니다.
각 곱셈이 실행되면 결과는 즉시 다음 곱셈-누산기로 전달되는 구조입니다.
여기서 중요한 점은 행렬 곱셈 과정 중에 메모리 접근이 필요 없다는 것입니다.
모든 중간 결과가 65,000개의 ALU 사이를 직접 전달되기 때문에 전력 소비가 크게 감소합니다.
Von Neumann 병목 현상의 해결
CPU와 GPU는 모두 폰노이만 아키텍처를 기반으로 합니다.
이 구조에서는 계산할 때마다 메모리에 접근해야 하는데, 메모리 통신 속도가 연산 속도보다 느려 병목 현상이 발생합니다.
TPU의 Systolic Array는 데이터를 한 번 읽으면 여러 연산에 재사용하는 방식으로 이 문제를 해결했습니다.
인접한 ALU끼리만 짧은 배선으로 연결되어 에너지 효율이 극대화되는 것이죠.
Google Cloud 공식 문서에 따르면, 이러한 구조 덕분에 TPU는 신경망 연산에서 CPU와 GPU보다 15~30배 빠른 성능을 보입니다.
Cloud TPU 소개 | Google Cloud Documentation
의견 보내기 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. Cloud TPU 소개 Tensor Processing Unit(TPU)은 Google에서 맞춤 개발한 ASIC(Application-Specific Integrated Circuit)로,
docs.cloud.google.com
TPU vs GPU: 무엇이 다른가
| 특성 | TPU | GPU |
|---|---|---|
| 설계 목적 | 머신러닝 전용 ASIC | 그래픽 렌더링 및 범용 병렬 처리 |
| 아키텍처 | Systolic Array | SIMT (수천 개의 CUDA 코어) |
| 연산 정밀도 | 저정밀도 연산 최적화 (8비트, bfloat16) | 고정밀 연산 지원 |
| 메모리 대역폭 | 상대적으로 낮음 (처리량 우선) | 매우 높음 (480GB/s 이상) |
| 에너지 효율 | 30~80배 향상 | 기준 |
| 범용성 | 신경망 특화 | 다양한 워크로드 |
| 확장성 | TPU Pod (최대 9,216 칩) | GPU 클러스터 |
성능 비교: 실제 벤치마크
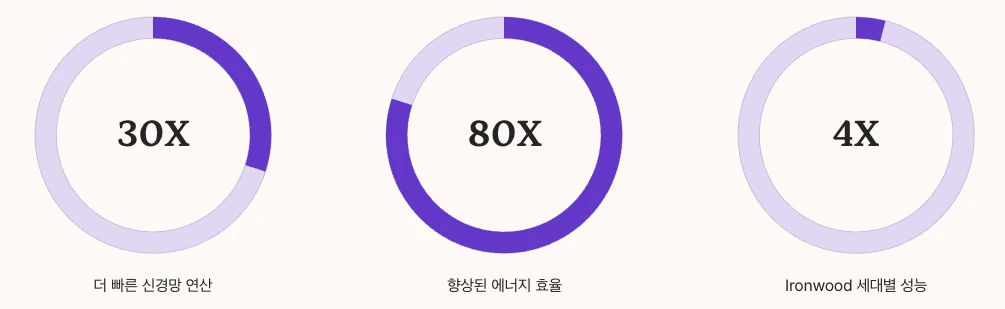
Google의 연구에 따르면 TPU는 신경망 기반 AI 추론 작업에서 현대 GPU와 CPU보다 15~30배 빠른 성능을 보입니다.
전력 효율 측면에서는 30~80배 향상된 TOPS/Watt(전력당 연산 성능)를 달성합니다.
특히 TPU v5p는 엔비디아 A100 대비 1.2-1.7배 빠르고 전력 효율은 1.3-1.9배 우수하다고 Google은 주장합니다.
2024년 출시된 Ironwood TPU는 이전 세대 대비 학습과 추론 모두에서 칩당 4배 이상의 성능 향상을 달성했습니다.
GPU의 장점: 유연성과 생태계
그렇다면 GPU는 어떤 장점이 있을까요?
GPU는 수만 개의 범용 코어를 통해 다양한 연산을 동시에 처리할 수 있는 유연성을 제공합니다.
NVIDIA의 Tensor Core와 같은 전용 유닛을 포함하여 혼합 정밀도 행렬 곱셈을 가속화합니다.
또한 CUDA, cuDNN과 같은 성숙한 개발 생태계를 갖추고 있어 개발자들에게 친숙합니다.
PyTorch, TensorFlow 등 거의 모든 머신러닝 프레임워크가 GPU를 기본적으로 지원합니다.
TPU의 경우 PyTorch/XLA나 JAX를 통해 활용할 수 있지만, GPU만큼 폭넓은 지원은 아직 제공되지 않습니다.
TPU의 세대별 발전
TPU v1 (2016)
최초의 TPU는 추론 전용으로 설계되었습니다.
256 x 256 Systolic Array로 초당 92테라옵스를 처리했죠.
Google 데이터센터 내부에서만 사용되었으며 외부에는 공개되지 않았습니다.
TPU v2 (2017)
학습 기능이 추가된 첫 번째 세대입니다.
4개의 칩을 연결하여 최대 180 TFLOPS의 성능을 발휘했습니다.
Cloud TPU 서비스를 통해 일반 개발자들도 접근할 수 있게 되었습니다.
TPU v3 (2018)
수랭식 냉각 시스템을 도입한 세대입니다.
TPU Pod는 100 PFLOPS 이상의 성능을 제공하며 대형 언어모델 학습에 활용되었습니다.
TPU v4 (2021)
한 Pod에 4,096개의 칩을 탑재하여 PaLM 언어모델(5,400억 매개변수)을 학습하는 데 사용되었습니다.
6,144개의 v4 칩이 1,200시간 동안 작동했다고 알려져 있습니다.
TPU v5 (2023)
효율성이 높은 v5e와 더 높은 성능의 v5p로 나뉩니다.
v5e는 경제적인 고성능 추론을 제공하며 Cloud TPU v4 대비 달러당 최대 2.5배 높은 처리량을 자랑합니다.
TPU v6e Trillium (2024)
2024년 5월 발표된 6세대 TPU입니다.
v5e보다 칩당 4.7배 향상된 성능을 제공하고, HBM 용량과 대역폭이 2배로 증가했습니다.
Google의 Gemini 2.0 모델이 이 TPU로 학습되었죠.
[I/O 2024] 구글 클라우드 TPU 6세대, 트릴리움(Trillium) 을 소개합니다
구글 역사상 가장 뛰어난 성능과 에너지 효율성을 자랑하는 최신 6세대 TPU ‘트릴리움(Trillium)’은 이전 세대 TPU v5e대비 칩당 컴퓨팅 성능이 4.7배 향상되었으며 연말 구글 클라우드 고객 대상 제
blog.google
Trillium은 AI Hypercomputer 아키텍처와 완전히 통합되어 있습니다.
TPU v7 Ironwood (2024)
2024년 11월 정식 공개된 최신 7세대 TPU입니다.
추론에 특화되어 설계되었으며, 최대 9,216개의 칩을 superpod로 확장할 수 있습니다.
Inter-Chip Interconnect(ICI) 네트워크는 9.6 Tb/s의 속도로 작동합니다.
Ironwood superpod는 1.77 Petabytes의 공유 HBM을 제공하여 가장 까다로운 모델도 처리할 수 있습니다.
흥미롭게도 Ironwood는 AI를 활용한 AlphaChip 방법론으로 설계되었습니다.
How AlphaChip transformed computer chip design
Our AI method has accelerated and optimized chip design, and its superhuman chip layouts are used in hardware around the world. AlphaChip was one of the first reinforcement learning approaches used t…
deepmind.google
강화학습을 사용하여 지난 3세대 TPU의 우수한 레이아웃을 생성한 것이죠.
TPU의 실제 활용 사례
Google 내부 서비스

Google 검색, Google 포토, Google 지도, Google 번역 등 10억 명 이상의 사용자를 보유한 모든 Google AI 애플리케이션이 TPU를 기반으로 합니다.
Google Street View는 TPU를 사용하여 전체 데이터베이스의 텍스트를 5일 이내에 처리했습니다.
Google 포토에서는 단일 TPU가 하루에 1억 장 이상의 사진을 처리합니다.
대형 언어모델
Google의 Gemini 시리즈는 모두 TPU로 학습되었습니다.
PaLM, LaMDA, Bard와 같은 대형 언어모델 개발에도 TPU가 핵심적인 역할을 했습니다.
외부 고객 사례
2024년 말, 메타는 Google TPU를 자사 데이터센터에 적용하는 방안을 검토 중이라는 소식이 전해졌습니다.
계약 규모는 수십억 달러로 추정되며, 2027년부터 자체 데이터센터에 TPU를 투입할 예정입니다.
Claude를 개발한 Anthropic은 Google과 최대 100만 개 규모의 TPU 공급 계약을 체결했습니다.
Apple Intelligence도 모델 학습 시 NVIDIA 카드 대신 Cloud TPU를 활용하는 것으로 알려져 있습니다.
“메타가 선택한 AI 가속기” TPU의 이해
TPU(Tensor Processing Unit)은 AI 가속을 위해 특별히 설계된 전용 AI 가속기이다. TPU는 특정 작업을 위해 설계된 칩인 ASIC의 한 종류로, 학습과 추론을 포함한 AI/ML 워크플로우를 실행하고 최적화하는 데
www.itworld.co.kr
Cloud TPU: 누구나 사용할 수 있는 AI 인프라
Google은 Cloud 인프라를 통해 TPU를 서비스로 제공합니다.
개발자들은 물리적 하드웨어를 구매하지 않고도 TPU의 강력한 성능을 활용할 수 있습니다.
Cloud TPU의 장점
유연한 확장성: 동적 워크로드 스케줄러를 통해 필요한 모든 가속기를 동시에 예약할 수 있습니다.
프레임워크 지원: TensorFlow, PyTorch, JAX 등 주요 AI 프레임워크와 통합됩니다.
Vertex AI 통합: 완전 관리형 AI 플랫폼에서 TPU를 쉽게 활용할 수 있습니다.
GKE 통합: Google Kubernetes Engine에서 대규모 AI 워크로드를 원활하게 조정할 수 있습니다.
무료 체험 옵션
개발자들은 Google Colab에서 무료로 TPU v5e-1을 사용해볼 수 있습니다.
Google Colab
colab.research.google.com
Kaggle에서도 TPU v3-8과 v5e-8을 무료로 제공합니다.
TRC(TPU Research Cloud) 프로그램을 통해 연구 결과를 공유하는 조건으로 1개월간 무료로 TPU를 사용할 수도 있습니다.
TPU Pod: 엑사스케일 컴퓨팅의 실현

TPU의 진정한 힘은 확장성에 있습니다.
TPU Pod는 고속 네트워크로 연결된 TPU 기기의 모음으로, 수백에서 수천 개까지 확장 가능합니다.
Ironwood의 경우 최대 9,216개의 칩을 단일 superpod로 구성할 수 있습니다.
이들은 9.6 Tb/s의 Inter-Chip Interconnect 네트워크로 직접 연결됩니다.
실제로 Google은 50,944개의 TPU v5e 칩으로 학습을 실행한 사례도 있습니다.
이러한 확장성 덕분에 음성 인식, 기계 번역, 추천 시스템, 이미지 생성 모델 같은 초대형 모델을 학습할 수 있습니다.
TPU Pod는 선형적으로 확장되도록 설계되어, 칩 수를 늘리면 그에 비례하여 성능이 향상됩니다.
TPU의 한계와 과제
제한된 접근성
TPU는 현재 물리 하드웨어로 직접 구매할 수 없습니다.
Cloud TPU 서비스를 통해서만 접근 가능하다는 점이 GPU와의 큰 차이점입니다.
소형 Edge TPU는 로컬 디바이스 애플리케이션용으로 제공되지만, 데이터센터용 TPU와는 성능이 다릅니다.
학습 곡선
TPU에 맞게 코드를 최적화하려면 추가적인 개발자 역량이 필요합니다.
XLA(Accelerated Linear Algebra) 컴파일러를 통해 모델을 TPU 실행 파일로 변환하는 과정이 필요하죠.
GPU 생태계에 비해 커뮤니티와 학습 자료가 상대적으로 부족한 것도 사실입니다.
범용성의 부족
TPU는 신경망 연산에 특화되어 있어 다른 워크로드에는 적합하지 않습니다.
문서 편집, 로켓 엔진 제어, 은행 거래 처리 등 일반적인 컴퓨팅 작업은 수행할 수 없습니다.
GPU는 게임, 비디오 편집, 과학 계산 등 다양한 분야에서 활용되는 반면, TPU는 AI에만 집중합니다.
미래 전망: AI 가속기 시장의 변화
TPU의 등장으로 AI 하드웨어 시장은 큰 변화를 맞이하고 있습니다.
2023년 모건 스탠리 리포트에 따르면 NVIDIA A100의 주요 고객 목록에 Google이 없는 것으로 나타났습니다.
이는 딥러닝 워크로드에서 TPU가 이미 NVIDIA의 역할을 대부분 대체했음을 시사합니다.
메타와 같은 빅테크 기업들이 TPU를 도입하면서 업계 전반의 연산 인프라 전략이 재편될 가능성이 높습니다.
ASIC의 시대
TPU의 성공은 특정 작업에 최적화된 ASIC의 가능성을 입증했습니다.
Microsoft의 Maia, Amazon의 Trainium과 Inferentia, Tesla의 Dojo 등 각 기업이 자체 AI 칩을 개발하고 있습니다.
범용 GPU에서 전용 AI 가속기로의 전환이 가속화되고 있는 것이죠.
에너지 효율의 중요성

AI 모델의 규모가 기하급수적으로 증가하면서 에너지 소비가 주요 과제로 떠올랐습니다.
Google CEO 순다르 피차이에 따르면 ML 컴퓨팅 수요는 지난 6년간 100만 배 증가했습니다.
대략 매년 10배씩 증가하는 수준이죠.
TPU v6e Trillium은 v5e 대비 67% 더 에너지 효율적이라고 합니다.
이러한 에너지 효율 개선 없이는 AI 발전이 지속 가능하지 않을 것입니다.
개발자를 위한 TPU 활용 가이드
TPU 시작하기
TPU를 처음 시작하는 개발자라면 Google Colab에서 무료로 실험해보는 것을 추천합니다.
런타임 유형을 TPU로 변경하면 즉시 사용할 수 있습니다.
TensorFlow 호환
TensorFlow 2.x 이상에서는 TPU 지원이 기본적으로 포함되어 있습니다.
import tensorflow as tf
resolver = tf.distribute.cluster_resolver.TPUClusterResolver()
tf.config.experimental_connect_to_cluster(resolver)
tf.tpu.experimental.initialize_tpu_system(resolver)
strategy = tf.distribute.TPUStrategy(resolver)PyTorch 활용
PyTorch 사용자는 PyTorch/XLA를 통해 TPU를 활용할 수 있습니다.
GitHub - pytorch/xla: Enabling PyTorch on XLA Devices (e.g. Google TPU)
Enabling PyTorch on XLA Devices (e.g. Google TPU). Contribute to pytorch/xla development by creating an account on GitHub.
github.com
XLA는 모델을 TPU에서 실행 가능한 형태로 컴파일합니다.
JAX 프레임워크
Google에서 개발한 JAX는 TPU와의 호환성이 매우 우수합니다.
고성능 수치 계산과 자동 미분을 제공하며 TPU에서 효율적으로 작동합니다.
결론: TPU가 AI 미래를 바꾸는 이유

Google의 Tensor Processing Unit은 단순한 하드웨어 혁신을 넘어 AI 개발 패러다임을 변화시키고 있습니다.
머신러닝 하드웨어로서 TPU는 신경망 연산에 최적화된 아키텍처로 GPU 대비 월등한 에너지 효율과 처리 속도를 제공합니다.
Systolic Array 구조를 통한 행렬 연산 가속은 대형 언어모델 시대의 핵심 기술입니다.
Cloud 인프라를 통해 누구나 접근할 수 있는 AI 가속기로 자리매김하면서, TPU는 AI 민주화에도 기여하고 있습니다.
메타, Anthropic, Apple과 같은 거대 기업들의 TPU 채택은 이 기술의 가치를 증명합니다.
ASIC 기반 AI 가속기의 시대가 열리면서, 각 기업이 자체 칩을 개발하는 추세는 더욱 가속화될 것입니다.
하지만 TPU의 제한된 범용성과 접근성은 여전히 극복해야 할 과제입니다.
GPU 생태계의 성숙도와 유연성을 따라잡기 위해서는 더 많은 시간과 투자가 필요할 것입니다.
그럼에도 불구하고 TPU는 AI 워크로드의 미래를 선도하는 기술로, 앞으로도 지속적인 발전이 기대됩니다.
딥러닝 칩 시장에서 TPU의 역할은 점점 더 커질 것이며, AI 추론과 학습의 효율성을 한 단계 더 끌어올릴 것입니다.
자주 묻는 질문 (FAQ)
Q: TPU를 개인적으로 구매할 수 있나요?
현재 데이터센터용 TPU는 물리적으로 구매할 수 없으며 Cloud TPU 서비스를 통해서만 이용 가능합니다.
다만 Edge TPU는 Coral 보드를 통해 구매할 수 있습니다.
Coral | Google for Developers
Open-source platform for edge AI accelerator chip development
developers.google.com
Q: TPU는 모든 머신러닝 작업에 적합한가요?
아니요. TPU는 행렬 연산이 많은 신경망 기반 작업에 최적화되어 있습니다.
컨볼루션 신경망, 트랜스포머 기반 모델 등에 적합하지만, 일부 강화학습이나 그래프 신경망에는 GPU가 더 나을 수 있습니다.
Q: GPU 대신 TPU를 선택해야 하는 경우는?
대규모 모델 학습, 추론 서빙, 비용 효율이 중요한 경우에 TPU가 유리합니다.
특히 TensorFlow를 사용하고 Google Cloud Platform을 활용한다면 TPU가 좋은 선택입니다.
Q: TPU v6e와 v7의 차이는 무엇인가요?
TPU v6e(Trillium)은 학습과 추론 모두에 강점이 있으며, v7(Ironwood)은 추론에 특화되어 있습니다.
Ironwood는 대규모 확장성과 낮은 지연시간을 제공합니다.
같이 보면 좋은 글
Gemini 3.0 완전해부 | 성능 변화·멀티모달 기능·실사용 팁·GPT 최신 모델 비교까지 한 번에 정리
구글의 Gemini 3.0은 GPT-5.1과 Claude 4.5를 제치고 LMArena 리더보드 1위를 차지한 최첨단 AI 모델로, 향상된 추론 능력과 멀티모달 이해력, 그리고 에이전트 기능을 통해 개발자와 일반 사용자 모두에게
notavoid.tistory.com
나노바나나 프로(Nano Banana Pro) 완전정리 | 기능·사용법·접근 방법·안전성·응용 사례까지
구글 DeepMind가 Gemini 3 Pro 기반으로 개발한 나노바나나 프로(Nano Banana Pro)는 텍스트 렌더링과 4K 이미지 생성을 지원하는 최첨단 AI 이미지 생성 모델로, 전문가용 크리에이티브 제어 기능과 실시간
notavoid.tistory.com
나노 바나나 프로 475개 프롬프트 공개 & 활용 가이드 | AI 이미지 생성 프롬프트 집대성
나노 바나나 프로(Nano Banana Pro)의 방대한 프롬프트 갤러리를 활용하면 전문가 수준의 AI 이미지를 단 몇 초 만에 생성할 수 있으며, 이 가이드에서는 475개 이상의 검증된 프롬프트 템플릿과 실전
notavoid.tistory.com
Claude Opus 4.5 벤치마크 정리 | 코딩·에이전트·툴-사용 우위 모델의 실력은?
Claude Opus 4.5는 SWE-bench Verified 80.9%, OSWorld 66.3%를 기록하며 코딩·에이전트·컴퓨터 사용 벤치마크에서 최고 성능을 달성한 Anthropic의 최신 플래그십 모델입니다.Claude Opus 4.5란 무엇인가 2025년 11월 2
notavoid.tistory.com
GPU란 무엇인가 | 그래픽 처리기부터 AI 컴퓨팅까지 확장된 코어 역할 완전정리
GPU는 그래픽 처리를 넘어 AI와 머신러닝의 핵심 연산장치로 진화했으며, 병렬처리 구조를 통해 CPU 대비 수십 배 빠른 대량 연산을 수행하여 딥러닝과 과학 컴퓨팅을 가속화하는 현대 컴퓨팅의
notavoid.tistory.com
'AI 트렌드 & 뉴스' 카테고리의 다른 글
| 인공지능 활용 사례와 AI 소프트웨어 사용법 및 윤리 총정리 (1) | 2025.12.02 |
|---|---|
| 빅데이터 분석 전략과 AI 융합으로 시장 선도하는 법 (0) | 2025.12.02 |
| AGI 개발 스택 완벽 가이드 데이터부터 하드웨어까지 (0) | 2025.12.01 |
| 웨어러블 IoT 피트니스 기기 구매 및 기능 완벽 가이드 (0) | 2025.12.01 |
| JSON vs TOON 비교 가이드 | LLM 시대에 맞는 데이터 포맷 선택법 (0) | 2025.11.30 |



