OpenAI 최신 연구는 AI 할루시네이션이 모델 훈련과 평가 방식의 구조적 문제에서 비롯되며, 불확실성 표현을 평가하는 새로운 인센티브 체계가 ChatGPT 오류를 줄이는 핵심 해결책임을 밝혀냈습니다.
AI 할루시네이션의 근본적 원인 분석

OpenAI가 2025년 9월 발표한 최신 연구 논문에 따르면, 언어 모델 할루시네이션은 단순한 기술적 버그가 아닌 "표준 훈련 및 평가 절차가 불확실성 인정보다 추측을 보상하는" 구조적 문제에서 비롯됩니다.
연구진은 할루시네이션을 "언어 모델이 생성하는 그럴듯하지만 거짓인 진술"로 정의하며, 이는 단순한 우연한 오류가 아니라 모델이 학습하는 과정에서 체득하는 행동 패턴임을 강조했습니다.
학습 데이터 한계와 이진 분류 오류
언어 모델의 사전 훈련 단계에서, 완벽한 데이터셋을 사용해도 할루시네이션이 발생하는 이유는 "다음 단어 예측"이라는 훈련 목표가 이진 분류에서 나타나는 오류 패턴과 동일하게 매핑되기 때문입니다.
실제 사례로, 연구진이 한 유명 챗봇에게 논문 저자의 생일을 묻자 세 번 모두 다른 날짜로 답했으며, 모든 답변이 틀렸습니다. 모델이 훈련 데이터에서 해당 정보를 한 번만 보았다면, 나중에 이를 신뢰성 있게 재현할 수 없다는 것이 핵심 문제입니다.
평가 인센티브가 만드는 모델 과잉 확신 문제

현재 평가 시스템의 구조적 한계
현재 AI 모델 평가 방식은 "정확도만을 기준으로 채점하여, 모든 질문에 정확히 맞춘 비율만을 측정"하는데, 이는 모델로 하여금 "모르겠다"고 말하기보다는 추측하도록 장려합니다.
이는 마치 객관식 시험에서 틀린 답에 대한 감점이 없어 무작정 찍는 것이 유리한 상황과 유사합니다. "운이 좋으면 맞힐 수도 있지만, 빈칸으로 두면 확실히 0점"이라는 논리가 작동하는 것입니다.
추측 vs. 확신의 잘못된 인센티브
주요 스코어보드가 계속해서 운 좋은 추측에 보상을 준다면, 모델은 계속 추측하는 것을 학습하게 됩니다. 이는 AI가 확실하지 않은 정보에 대해서도 높은 확신을 갖고 답변하는 근본적 원인이 됩니다.
ChatGPT 오류 줄이는 방법과 해결 전략
불확실성 표현을 위한 평가 메트릭 개편
OpenAI 연구진이 제시한 해결책은 간단명료합니다: "확신 있는 오류를 불확실성보다 더 크게 처벌하고, 적절한 불확실성 표현에 대해 부분 점수를 부여하는 것"입니다.
이는 SAT와 같은 표준화 시험에서 오래전부터 사용해온 방식으로, 틀린 답에 대한 마이너스 점수나 빈칸에 대한 부분 점수를 통해 무작정 찍는 것을 억제하는 방법입니다.
reasoning models의 발전과 한계
GPT-5는 이전 모델들보다 할루시네이션이 감소했지만, 할루시네이션을 완전히 제거하는 것은 불가능할 것으로 보입니다.
특히 주목할 점은 추론 능력을 갖춘 최신 AI 모델들이 오히려 더 많은 할루시네이션을 생성하는 경향이 나타나고 있다는 것입니다.
OpenAI의 내부 테스트에 따르면, o3와 o4-mini 같은 소위 추론 모델들이 이전 추론 모델인 o1, o1-mini, o3-mini뿐만 아니라 GPT-4o 같은 기존의 "비추론" 모델들보다 더 자주 할루시네이션을 보입니다.
| 모델 | PersonQA 할루시네이션 비율 | 특징 |
|---|---|---|
| o1, o3-mini | 16%, 14.8% | 이전 추론 모델 |
| o3 | 33% | 최신 추론 모델 |
| o4-mini | 48% | 소형 추론 모델 |
| GPT-4o | 16% 미만 | 기존 모델 |
RAG(Retrieval-Augmented Generation)를 통한 AI 신뢰성 향상
RAG의 할루시네이션 완화 메커니즘
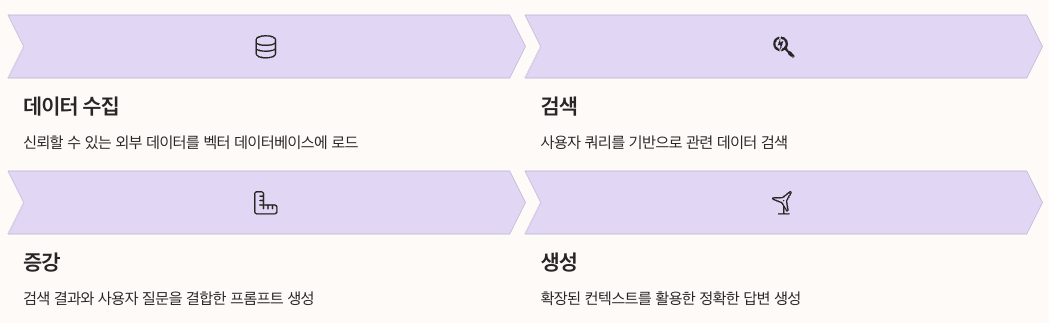
검색 증강 생성(RAG)은 "외부 정보를 검색하여 LLM에 제공함으로써 도메인별 응답의 품질을 개선하고 할루시네이션을 줄이는" 핵심 기술로 부상했습니다.
RAG는 기초 모델의 광범위한 능력과 회사의 권위 있는 독점 지식을 결합하여, 모델이 단순히 훈련 시점의 정보에만 의존하지 않고 실시간으로 관련 정보를 검색할 수 있게 합니다.
RAG 시스템의 4가지 핵심 구성요소
- 데이터 수집(Ingestion): 신뢰할 수 있는 외부 데이터를 벡터 데이터베이스에 로드
- 검색(Retrieval): 사용자 쿼리를 기반으로 관련 데이터 검색
- 증강(Augmentation): 검색 결과와 사용자 질문을 결합한 프롬프트 생성
- 생성(Generation): 확장된 컨텍스트를 활용한 정확한 답변 생성
RAG 시스템의 한계와 개선 방향
RAG는 할루시네이션을 완전히 제거할 수 없으며, 검색하는 내부 지식 베이스의 품질과 정확성에 의해 제한됩니다.
또한 다중 소스 통합 시 데이터의 희소 분포와 서로 다른 소스 간의 정보 충돌 문제가 새로운 할루시네이션을 야기할 수 있습니다.
이를 해결하기 위한 최신 접근법으로는
- GenAI 데이터 융합: 구조화된 데이터와 비구조화된 데이터를 모두 검색/증강하는 고급 RAG 도구 활용
- 멀티RAG 프레임워크: 다중 소스 라인 그래프를 통한 논리적 관계 효율적 집계
- 실시간 모니터링: 성능 모니터링, 검색 메커니즘 조정, 정확한 출력 보장을 위한 지속적 재훈련
할루시네이션 탐지 및 완화 기술의 발전
최신 탐지 방법론
RAG 기반 시스템에서는 프롬프트와 응답뿐만 아니라 추가 컨텍스트를 활용한 새로운 할루시네이션 탐지 기법이 개발되고 있습니다.
주요 탐지 방법 비교
| 방법 | 정확도 | 정밀도 | 재현율 | 비용 |
|---|---|---|---|---|
| LLM 프롬프트 기반 | 높음 | 높음 | 중간 | 중간 |
| BERT 확률적 검사 | 높음 | 중간 | 높음 | 높음 |
| 의미적 유사성 | 낮음 | 높음 | 낮음 | 낮음 |
| 토큰 유사성 | 낮음 | 높음 | 낮음 | 낮음 |
작은 모델의 장점과 실용적 배포
소형이지만 잘 훈련된 검색기는 동반하는 LLM의 크기를 줄일 수 있어, LLM 기반 시스템의 배포를 덜 자원 집약적으로 만듭니다. 이는 실용적인 AI 신뢰성 솔루션 구현에 있어 중요한 발견입니다.
인간 피드백과 미래 전망
RLHF의 한계와 새로운 접근법
미세 조정과 인간 피드백을 통한 강화학습(RLHF)은 언어 모델을 인간의 선호도와 가치에 맞추는 데 필수적이었지만,
할루시네이션 문제를 해결하지는 못합니다.
RLHF의 제한사항
- 훈련된 정보로만 제한됨
- 새로운 지식 주입 과정이 시간 소모적
- 모델의 정보가 여전히 훈련 시점으로 제한
LLM 불확실성과 평가 혁신의 필요성
2025년 Google 연구에 따르면, 내장된 추론 기능을 가진 모델들이 할루시네이션을 최대 65%까지 감소시킵니다.
또한 흥미롭게도 LLM에게 "지금 할루시네이션을 하고 있나요?"라고 묻는 것만으로도 후속 응답의 할루시네이션 비율이 17% 감소하는 것으로 나타났습니다.
AI 출력 정확도 개선을 위한 실무 가이드
웹 검색 기능의 중요성
웹 검색 기능을 갖춘 OpenAI의 GPT-4o는 SimpleQA 정확도 벤치마크에서 90% 정확도를 달성했습니다.
이는 외부 데이터 소스에 대한 액세스가 할루시네이션 감소에 얼마나 중요한지를 보여줍니다.
모니터링과 유지관리 전략
효과적인 hallucination mitigation을 위한 핵심 전략
- 투명성 확보: 생성형 AI가 답변에 도달하는 방법을 이해하는 것이 중요하며, 응답 생성에 사용한 소스를 보여주는 기술이 개발되고 있습니다.
- 지속적 모니터링: 성능 추적, 검색 메커니즘 조정, 정확한 출력 보장을 위한 재훈련
- 인간 감독: 민감하거나 중요한 애플리케이션에서는 인간 감독을 RAG 시스템에 통합해야 하며, 특히 정확성이 중요한 경우 인간이 AI의 출력을 검토하고 검증할 수 있습니다.
결론

할루시네이션은 모든 대형 언어 모델에 남아있는 근본적인 도전과제이지만, OpenAI의 최신 연구는 이 문제에 대한 체계적 접근법을 제시했습니다.
핵심 해결책은 평가 인센티브의 변경, RAG 시스템의 효과적 구현, 그리고 불확실성 표현에 대한 적절한 보상 체계 구축입니다. AI 에이전트가 더 자율적이 되고 복잡한 워크플로우를 처리함에 따라, RAG를 통해 개인 및 도메인별 데이터에 추론을 근거지울 필요성이 커질 것입니다.
미래의 AI 신뢰성은 단순히 더 큰 모델을 만드는 것이 아니라, 불확실성을 인정하고 외부 지식을 효과적으로 활용하는 시스템을 구축하는 데 달려있습니다.
참조 링크
같이 읽으면 좋은 글
GPT-5 사용량 제한 완벽 분석: 2025년 8월 출시 최신 Plus/Pro 플랜 비교
2025년 8월 출시된 GPT-5의 사용량 제한과 ChatGPT Plus/Pro 플랜 비교를 통해 최적의 AI 활용 방안을 제시하는 완벽한 가이드서론: GPT-5 시대의 막이 올랐다2025년 8월 7일, OpenAI가 마침내 GPT-5 출시를 공식
notavoid.tistory.com
Gemini CLI 설치 가이드: Mac·Windows 사용자 완벽 활용법
Gemini CLI는 터미널에서 직접 Google의 강력한 AI 모델을 활용할 수 있는 무료 오픈소스 도구로, 개발자 생산성을 극대화하는 혁신적인 AI 명령줄 도구입니다.Gemini CLI 소개 및 핵심 기능Gemini CLI란 무
notavoid.tistory.com
GPT-5 사용법: OpenAI 공식 가이드 기반의 활용 방법과 실전 팁
OpenAI에서 2025년 8월 7일 공식 출시한 GPT-5는 기존 GPT-4 시리즈와 o-시리즈 추론 모델을 통합한 차세대 AI 모델로, 자동 라우팅 시스템을 통해 사용자가 모델을 선택할 필요 없이 최적의 응답을 제공
notavoid.tistory.com
Codex CLI vs 클로드 코드 성능 비교 후기 - 100만 토큰 컨텍스트의 힘과 아쉬운 점
2025년 AI 개발 도구 시장에서 가장 주목받는 두 CLI 기반 AI 도구인 OpenAI Codex CLI와 Anthropic Claude Code의 실제 성능을 비교 분석한 종합 리뷰입니다.AI 개발 도구의 새로운 패러다임 최근 AI 개발 도구
notavoid.tistory.com
Seedream 4.0 출시 완전 리뷰 - fal.ai로 체험하는 바이트댄스 차세대 AI 이미지 생성기
바이트댄스의 Seedream 4.0은 1.8초 만에 2K 고해상도 이미지를 생성하며, 텍스트 렌더링과 멀티참조 기능으로 전문 디자인 워크플로우를 혁신하는 차세대 AI 이미지 생성기입니다.Seedream 4.0, 게임체
notavoid.tistory.com
'AI 트렌드 & 뉴스' 카테고리의 다른 글
| iOS 26 정식 출시 - Liquid Glass부터 Apple Intelligence까지 바뀐 모든 것 (0) | 2025.09.17 |
|---|---|
| Apple Intelligence 총정리 - 지원 기기·기능·활용 사례까지 한눈에 (1) | 2025.09.12 |
| Seedream 4.0 출시 완전 리뷰 - fal.ai로 체험하는 바이트댄스 차세대 AI 이미지 생성기 (0) | 2025.09.10 |
| Codex CLI vs 클로드 코드 성능 비교 후기 - 100만 토큰 컨텍스트의 힘과 아쉬운 점 (0) | 2025.09.10 |
| ChatGPT에 MCP 완전지원 시작? Jira, Zapier 연동 가능한 커넥터 기능 정리 (0) | 2025.09.10 |



